
1 Introduction
Medical image segmentation refers to identifying the region of interest, typically anatomical structures or tumors, in an image. This process is essential in the field of medical image analysis, significantly contributing to the effectiveness of computer-aided diagnosis [1]. The introduction of deep learning techniques has led to a variety of automated segmentation methods [57, 85], further enhancing the precision and efficiency of analyzing medical images. Despite the progress made, it is still difficult to determine the most effective method for developing an optimal segmentation model, especially with the recent introduction of vision foundation models dedicated to segmentation. Therefore, in our study, we aim to explore and define the optimal strategies for developing automated segmentation algorithms specifically designed for medical images and with a focus on foundation models.
In the era of deep learning, a common practice for automated medical image segmentation is to directly train UNet [70] or its variants [75, 83] for a dataset and task. Recently, there has been a growing interest in the field of customizing vision foundation models towards specific segmentation tasks [96, 29]. Foundation models are (typically transformer-based [82]) neural networks pre-trained with extremely large datasets, such that they can generalize to a wide range of tasks and datasets. The seminal Segment Anything Model (SAM) [45] was proposed as the first large model designed with segmentation tasks in mind. SAM employs a prompt-based training method, aiming to generate target object’s segmentation masks in response to user-provided prompts, e.g. points or bounding boxes. It has demonstrated comparable or even superior zero-shot performance to fully supervised models in processing natural images. However, SAM’s performance is less impressive when directly applied to medical images [61, 21, 39], and the requirement of prompts makes the direct usage of it with medical imaging segmentation tasks challenging.
Removing the prompt requirement in SAM is relatively straightforward as we can use “dummy” prompt embeddings as inputs during fine-tuning, a strategy verified by concurrent work [96]. However, the approaches proposed for adapting SAM to medical imaging tasks vary widely. Some works focused on adapting SAM’s decoder only [92], while others chose to modify the entire network [96]. Some works introduced an additional pre-training stage [59] using multiple medical images while others usually do not. Though some prior survey work [49, 98] have attempted to list different strategies and categorize them into various groups, questions remain regarding (1) which fine-tuned strategy is the most effective, (2) whether these models can achieve better performance than traditional UNets and (3) whether using additional data is helpful.
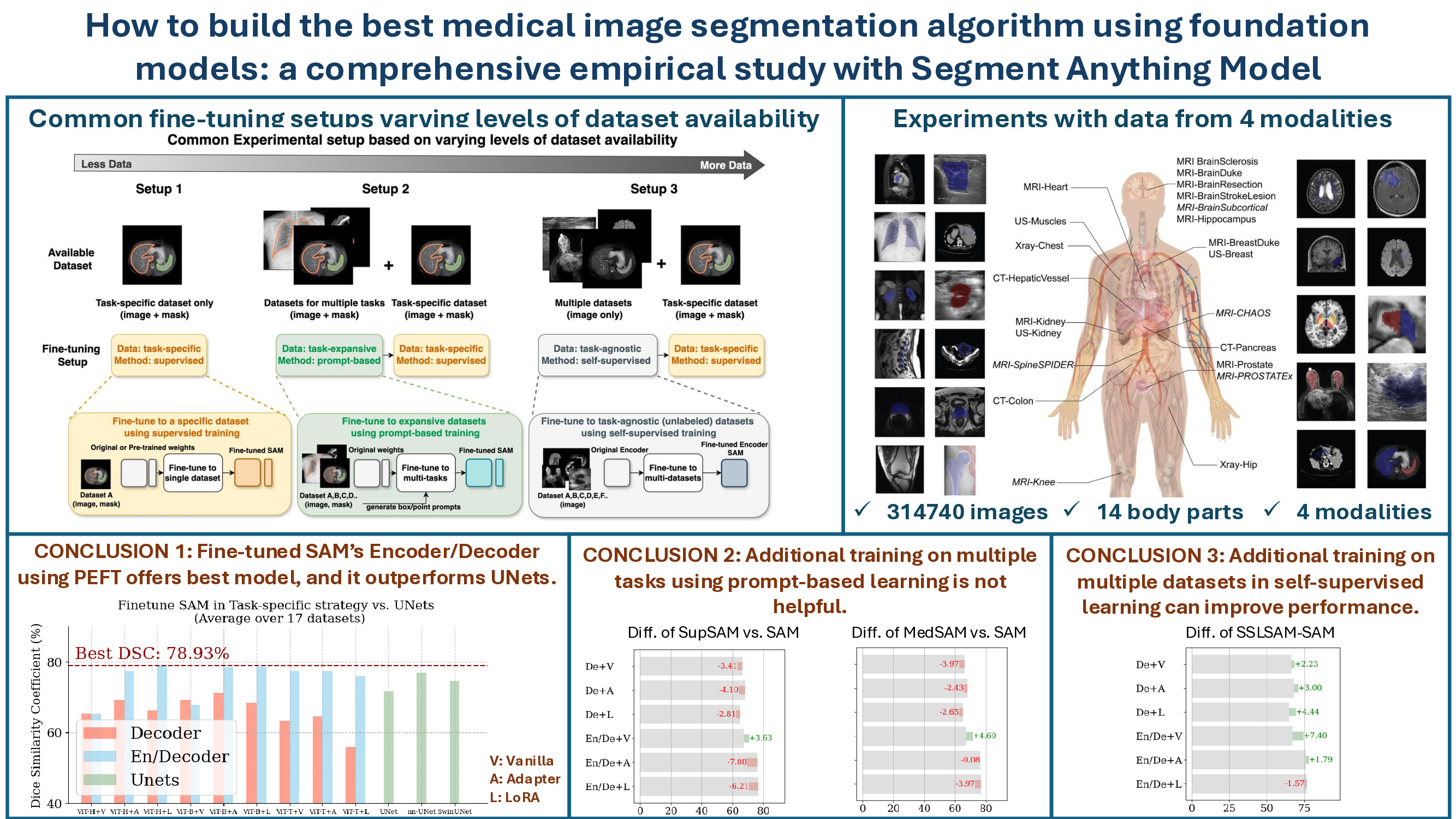
In this work, we aim to answer these questions by considering three common dataset availability scenarios in the medical imaging field: (1) only a single labeled dataset; (2) multiple labeled datasets for different tasks; and (3) multiple labeled and unlabeled datasets. The first scenario reflects the most common deep learning scenario of adapting SAM to the dataset of interest, and the latter two scenarios bring the opportunity to first incorporate broad medical domain knowledge into SAM using supervised/self-supervised training before adapting it to a specific dataset. Figure 1 summarizes the strategies and experiment setups we include. To avoid terminology confusion, we name these strategies as task-specific supervised training, task-expansive prompt-based learning, and task-agnostic self-supervised learning respectively.
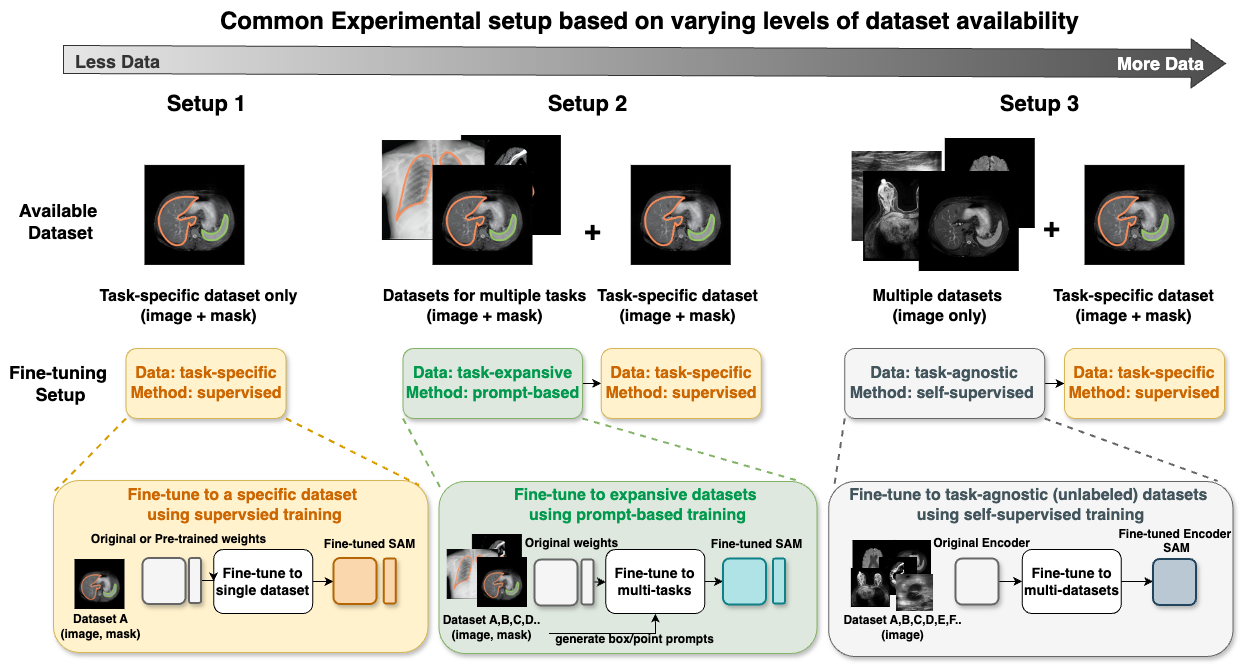
When considering the design choice during task-specific supervised training, our work aligns with several concurrent works [49, 98, 99]. However, our work differs from theirs in that we conduct comprehensive experiments over medical imaging datasets across various modalities for a fair comparison, rather than simply compiling disparate results, and provide an organized and new catalog that could summarize existing approaches. The choice of each category is shown in Figure 2 and will be discussed in Section 2.2. Our category definition reflects the common design choices when building a segmentation algorithm from SAM, and we can categorize most existing works based on the proposed criteria, shown in Table 1.
When incorporating extra medical knowledge into SAM, we explore two main setups of pre-training approaches: task-expansive prompt-based learning and task-agnostic self-supervised learning, depending on the availability of labels. Note that our objective is not to propose a novel pre-training strategy, as such strategies are often constrained by the availability of computation resources and datasets. Instead, our focus is on identifying if additional pre-training with more available medical data is helpful and if it is, to determine what is the best combination of pre-training and task-specific fine-tuning. Therefore, we adopt the strategies used during SAM’s development and one of the most commonly applied pre-training strategies in this field. Namely, we use the same interactive training pipeline where prompts are simulated from the masks for task-expansive prompt-based learning; and masked autoencoding (MAE) [31] as the objective for task-agnostic self-supervised learning. We evaluate these approaches on the same 17 datasets.
Our study is extended to two crucial scenarios when deploying a segmentation algorithm for annotation purposes: few-shot learning and interactive segmentation. The first scenario reflects the case of annotating a new dataset with only a limited number of annotations, while the latter examines the effectiveness of using tools to assist the annotation process. In both scenarios, we limit the evaluation datasets to MRI. When conducting few-shot learning, we limit the number of training samples to 5 and re-examine the effectiveness of setups 1-3 described in Figure 1. In the interactive segmentation scenario, we focus on task-specific supervised training with either box or point as input prompts.
In conclusion, we systematically study different approaches to fine-tune SAM in the medical imaging field. Our paper investigates an important question: what is the best practice to develop an automated segmentation algorithm based on foundation models? We find the answers depend on the availability of the datasets and consider three scenarios: (1) only a single labeled dataset; (2) multiple labeled datasets (with different objects of interest); and (3) multiple labeled and unlabeled datasets. We propose task-specific supervised training, task-expansive prompt-based learning followed by task-specific supervised training, and task-agnostic self-supervised learning followed by task-specific supervised training as the solution to each scenario respectively. By conducting systematic experiments on each strategy, we observe several useful guidelines and summarize them in Section 5.
2 Method
In this section, we first recapitulate SAM’s structure. Next, we describe the selected methods under different data availability scenarios.
2.1 SAM and removal of prompts
To begin with, we first briefly present an overview of the Segment Anything Model (SAM) [45] before introducing the fine-tuning strategies. SAM consists of three components: (1) image encoder, (2) prompt encoder, and (3) mask decoder. The image encoder, built on a robust Vision Transformer (ViT) framework, effectively converts a 2D image into a latent feature representation. Notably, in SAM’s original architecture, the image encoder offers flexibility in model size, with options including ViT-H(uge), ViT-L(arge), and ViT-B(ase) [22]. The prompt encoder is flexible, accommodating different prompt types such as point, box, or mask prompts. Depending on the input type, it generates either sparse embeddings for point/box prompts or dense embeddings for mask prompts. Lastly, the mask decoder is a transformer decoder using two-way cross-attention that integrates image and prompt embeddings to produce a multi-channel mask output, each channel representing varying confidence levels.
2.1.1 Interactive segmentation to automated segmentation
When converting SAM to auto-mode (without prompts), we can simply use the default embeddings generated by using “None” as inputs to the prompt encoder, i.e.
sparse_embeddings, dense_embeddings = sam.prompt_encoder(points=None, boxes=None, masks=None),
where the “sparse_embeddings” and “dense_embeddings” serve as inputs to SAM’s mask decoder. Empirical evidence shows the effectiveness of this simple approach [96]. More advanced methods, including adding a detection network to automatedally generate box prompts or a self-prompt module into SAM’s structure [87, 27, 72], are feasible but will introduce extra complexity into SAM’s structure, hampering our analysis on the effectiveness of fine-tuning strategies. Moreover, we believe our work offers a potentially effective strategy, i.e. feeding the generated prompts to the fine-tuned SAM instead of the original one, for this research direction.
2.2 Variables in task-specific supervised training
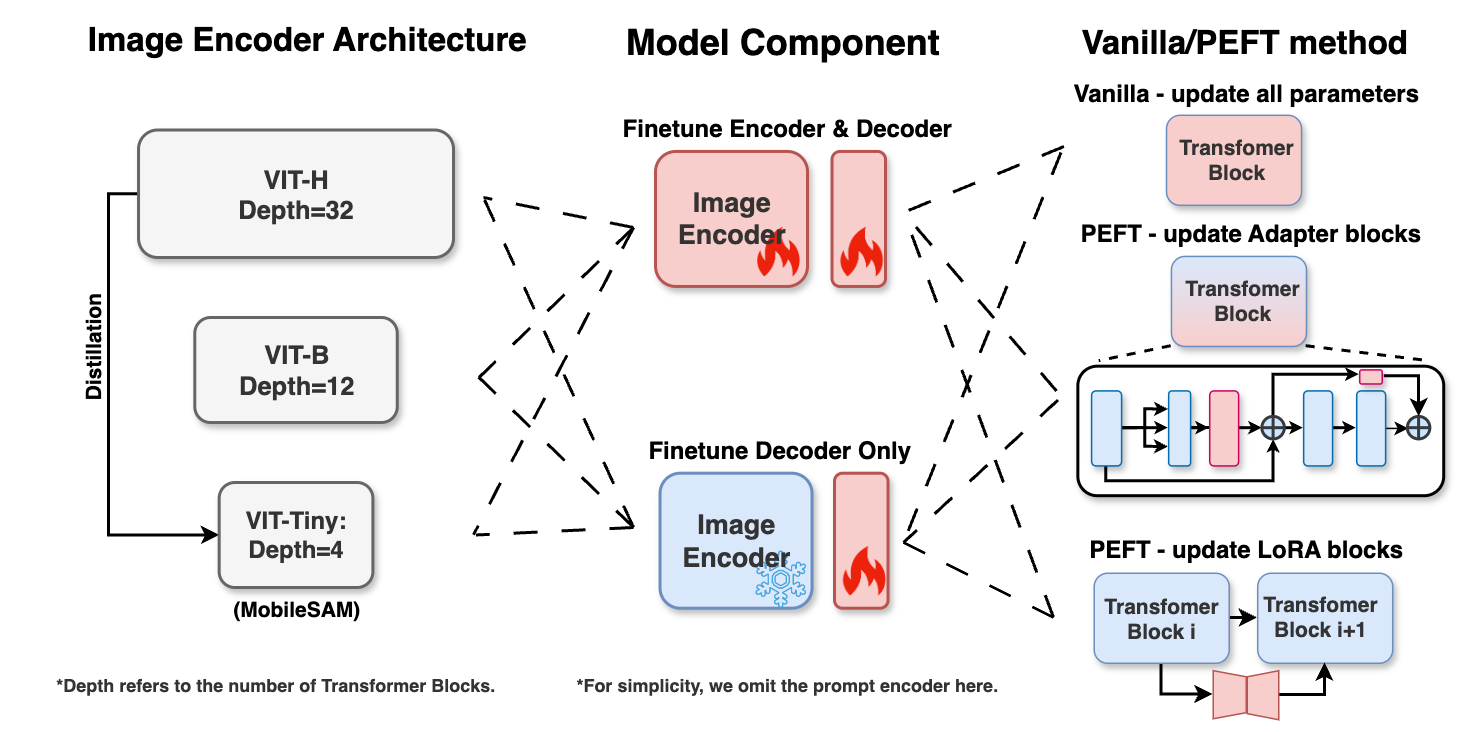
We consider three aspects in task-specific supervised training that can affect the performance, as shown in Figure 2. The choice of each category is discussed next.
2.2.1 Image Encoder Architecture
In this work, we select ViT-B and ViT-H from SAM’s provided checkpoints because they represent the most efficient and effective versions of SAM’s encoder respectively. Additionally, we explore a more compact option: ViT-T(iny). This backbone is introduced in MobileSAM [94], where the authors distill the knowledge from SAM’s pre-trained ViT-H to ViT-T, a customized vision transformer with of the network parameters and offers an inference speed times faster compared to the original SAM. The lightweight nature can widen the application of SAM, ease the computational requirements, and, more importantly, raise interesting research questions, such as whether distillation can maintain or even lead to the superior performance of SAM during fine-tuning.
2.2.2 Model Component
When selecting which set(s) of SAM’s parameters to update, the most straightforward way is to select one or multiple components from SAM. As discussed in Section 2.1.1, we use the default prompt embeddings and thus can keep the prompt encoder as is.
Some methods state the effectiveness of maintaining the encoder’s weights and only adapting the lightweight mask decoder of SAM’s architecture, as shown in Table 1. These approaches are grounded in the understanding that SAM’s encoder, trained on a comprehensive collection of natural images, is adequately powerful and knowledgeable in the general imaging domain with zero-shot ability to perform feature extraction, and updating the lightweight decoder can enhance performance in specific applications. Also, it is suggested that fine-tuning the encoder of SAM would demand considerably higher computational resources. However, due to the significant appeal difference between natural images and medical images, it remains unclear if SAM’s encoder could effectively capture the distinctive features of medical images without any modifications to the image encoder. Therefore, we consider these two choices: mask decoder only and mask decoder plus image encoder.
| Category | Methods | Dataset | Backbone | |
| Decoder + Vanilla | SAM for medical images? [39] | COSMOS 1050K | ViT-H / ViT-B | |
| Generalist Vision Foundation [73] | Multiple | ViT-H | ||
| How to efficiently [38] | ACDC [8] | ViT-H | ||
| All-in-SA [19] | Monuseg [47] | ViT-H | ||
| AdaptiveSAM [64] | Multiple | ViT-B | ||
| SkinSAM [37] | HAM10000 [80] | ViT-B | ||
| DeSAM [27] | Multi-Prostate | ViT-H | ||
| SurgicalSAM [92] | EndoVis [3] | ViT-H | ||
| SAM3D [11] | Multiple | ViT-B | ||
| SAM Fewshot [88] | Multiple | N/A | ||
| Decoder + LoRA | BLO-SAM [97] | Multiple | ViT-B | |
| Encoder + Vanilla | AutoSAM [72] | Multiple | ViT-H | |
| SAMUS [56] | Multiple | N/A | ||
| En/Decoder + Vanilla | Polyp-SAM [55] | Multi-Colonoscopy | ViT-L / ViT-B | |
| CellViT [34] | Multi-nuclei | ViT-H | ||
| En/Decoder + LoRA | Customized SAM [96] | Multi-Organ | ViT-H / ViT-B | |
| MA-SAM [14] | BTVC [24] | ViT-H | ||
| Cheap Lunch [25] | BraTS 18 [62] | ViT-B | ||
| En/Decoder + Adapter | Medical SAM Adapter [86] | BTVC [24] | ViT-H | |
| SAM Fails to Segment? [17] | kvasir-SEG [42] | ViT-H | ||
| Learnable Ophthalmology SAM [67] | Multiple | N/A | ||
| Auto-Prompting SAM [53] | Multiple | LightWeight ViT | ||
| SAM-Med2D [18] | SAM-Med2D [18] | ViT-B | ||
| 3DSAM-adapter [28] | Multi-CT | ViT-B | ||
| SAM-Path [95] | Multiple | LightWeight ViT | ||
| Self-Sampling Meta [51] | ABD-30 [48] | ViT-B | ||
| Cross-modality [74] | MRI | ViT-B |
2.2.3 Vanilla or Parameter-efficient Fine-tuning Method
When conducting model fine-tuning or transfer learning, the easiest and most intuitive way is to update all model parameters involved when feeding medical domains of data, which is vanilla fine-tuning [6].
Recently, parameter-efficient fine-tuning (PEFT) techniques have gained an increasing amount of attention. Compared with vanilla fine-tuning, PEFT keeps most of the network parameters fixed and only updates a small percentage, i.e. less than , of them. Such a strategy significantly reduces the computational cost and is beneficial in preventing catastrophic forgetting as well as over-fitting [23]. The simplest PEFT techniques involve selecting and fine-tuning a subset of the parameters from the original pre-trained model. These selective methods concentrate on identifying the optimal parameters for fine-tuning, aiming to strike an ideal balance between parameter efficiency and overall model performance. For instance, BitFit [93] proposed fine-tuning only the bias term in a transformer-based network, and Tinytl [12] shares a similar idea but focuses on CNN-based networks. Touvron et al. [79] have demonstrated the effectiveness of selectively fine-tuning only the attention layers in Vision Transformers (ViTs), whereas alternative approaches suggest that exclusively optimizing the normalization layers [7].
Rather than updating certain selected layers, recent research [54] indicates that incorporating extra modules into the large models appears to be more beneficial because it re-configures models towards a downstream task than solely updating network parameters. Among these additional module methods, Adapters, which were originally introduced for learning multi-domain representations [68, 69], have emerged as a particularly prevalent choice. In addition to the conventional Adapter block [35], Low-Rank Adaptation (LoRA), known for its efficient low-rank matrices added into self-attention layers that require even fewer parameters, has also gained popularity [36]. Additionally, AdaptFormer [15], which integrates a scalable Adapter into the multi-layer perceptron (MLP) layer of the attention block specifically for vision transformers, has shown that adding just 2% extra parameters can surpass the performance of fully fine-tuned networks across various natural imaging benchmarks. In our study, we aim to investigate the effectiveness of applying PEFT for fine-tuning SAM within the medical imaging domain. Considering Adpater and LoRA are the most popular PEFT methods adopted in LLMs and vision foundation transformers [91], we choose to include them as well as the simplest Vanilla for our experiments. In summary, we select the following methods:
- 1.
Vanilla - a “baseline” approach that updates all parameters.
- 2.
Adapter / LoRA - these approaches involve adding extra layers with original parameters fixed.
2.2.4 Summary
To sum up, we choose the following combinations to fine-tune SAM’s performance for specific datasets or tasks, as illustrated in Figure 2: (1) Variations in the image encoder’s architecture, including ViT-H, ViT-B, and ViT-T from MobileSAM [94]. (2) Different approaches to the fine-tuning scope of the network, encompassing both the encoder and decoder updates, as well as the decoder only. (3) Diverse parameter updating settings, comprising Vanilla, PEFT with Adapter blocks, and PEFT with LoRA blocks. By integrating these three variables, we present a total of distinct architectures for fine-tuning SAM on task-specific supervised training setup.
| Alias in our paper | Description and citation | # of images | # of masks |
| Datasets used for dataset-specific fine-tuning and pre-training: | |||
| MRI-BrainSclerosis (MRI-Scler.) | Brain Sclerosis with Lesion Segmentation[63] | ||
| MRI-BrainDuke (MRI-Brain) | Brain with FLAIR Abnormality Segmentation Masks[10] | ||
| MRI-BrainResection (MRI-Resect.) | EPISURG Segmentation on the Resection CaViTy[66] | ||
| MRI-BrainStrokeLesion (MRI-Stroke.) | ISLES 2022: Stroke Lesion Segmentation[33] | ||
| MRI-BreastDuke (MRI-Breast) | Breast Cancer Screening[71, 52] | ||
| MRI-Heart | Medical Segmentation Decathlon Cardiac[4] | ||
| MRI-Hippocampus (MRI-Hippo.) | Medical Segmentation Decathlon Hippocampus Head and Body[4] | ||
| MRI-Kidney | T2-weighted Kidney MRI[20] | ||
| MRI-Prostate (MRI-Prost.) | Original Multi-Parametric MRI Images of Prostate[50] | ||
| CT-Colon | Medical Segmentation Decathlon Colon[4] | ||
| CT-HepaticVessel (CT-vessel) | Medical Segmentation Decathlon Hepatic Vessel[4] | ||
| CT-Pancreas (CT-Panc.) | Medical Segmentation Decathlon Pancreas[4] | ||
| US-Breast | Breast Ultrasound Images Dataset[2] | ||
| US-Kidney | Kidney Segmentation in Ultrasound Images[77] | ||
| US-Muscle | Transverse Musculoskeletal Ultrasound images[60] | ||
| Xray-Chest | Montgomery County and Shenzhen Chest X-ray Datasets[41] | ||
| Xray-Hip | X-ray Images of the Hip Joints[30] | ||
| Datasets used for pre-training only: | |||
| MRI-BrainSubcortical | 14 Brain Sub-cortical Structures[76] | ||
| MRI-CHAOS | Segmentation of Liver, Kidneys and Spleen from MRI data[44] | ||
| MRI-Knee | MRNet Knee MRI Examinations[9] | Not used | |
| MRI-ProstateX | ProstateX Dataset of Prostate MR Studies[5] | ||
| MRI-SpineSPIDER | SPIDER - Lumbar Spine Segmentation in MR Images[81] | ||
2.3 Task-general Prompt-based Learning
When multiple labeled datasets are available, an approach to adapting SAM to the medical imaging field involves additional pre-training, i.e. starting with SAM’s pre-trained weights and continuing the learning process with a compilation of the medical datasets, followed by task-specific supervised training, as is similar in [18, 59]. The procedure is illustrated in Figure 1 setup . The motivation for adopting a two-step training approach, rather than utilizing automated fine-tuning on multiple datasets, lies in the fact that various datasets, despite featuring medical images of the same anatomical area and being captured using the same imaging technique, may concentrate on entirely distinct objectives. For example, two brain MRI datasets might each focus on segmenting different entities, such as the hippocampus in one and tumors in the other. Applying automated segmentation to these datasets could introduce ambiguity, and make the training challenging.
Therefore, we use a prompt-based segmentation setup during task-expansive prompt-based learning, which involves providing prompts to identify the targeted area of interest interactively. This approach addresses the issue of the above-mentioned ambiguity. Furthermore, this choice conceptually aligns with the second phase of SAM’s second-stage training process [45], allowing it to be considered as an extra step of supervised training specifically tailored for medical images within the SAM framework.
To simulate a prompt, we first randomly selected a type of object if the ground truth mask contains multiple objects. Then, for each contiguous region of the selected object, we generate a box or a point prompt with equal probability. The generation of box prompts follows SAM’s strategy: a tight box containing the target box is created first, followed by some random noises added to both locations. The random noises are generated with the standard deviation equal to of the box coordinates and to a maximum of pixels. For point generation, we follow [61] to first compute the distance of each pixel to its closet edge within the object region and sample a pixel with a distance above the median distance. This operation allows us to sample a point prompt around the center of the object. Such a design choice is different from that of the SAM, which samples the first point prompt uniformly and subsequent points from the error region between the previous mask prediction and the ground truth mask. Since our ultimate goal is to learn an automated segmentation algorithm, we do not need the iterative process to refine the predictions based on prompts.
Considering the differences across various medical imaging modalities, alongside the observation that images within the same modality often share similar visual features [46], we emphasize the value of modality-specific dataset knowledge in pre-training, a practice also common in the literature [78]. Specifically, we focus on the supervised pre-training on MRI, which consists of most of the collected datasets.
2.4 Task-agnostic Self-supervised Learning
When using multiple unlabeled medical image datasets, we can utilize the same idea as in the last section to conduct additional pre-training before applying task-specific supervised training. As the label information is unavailable in this scenario, we adapt the self-supervised learning (SSL) techniques, referred to as task-agnostic self-supervised learning. SSL refers to training a network without any human-collected labels. This is an effective strategy since the number of available datasets can increase dramatically. Popular SSL methods generally fall into two categories: contrastive learning [32, 16, 65] or masked image modeling [31, 90]. In the medical image field, further methods are tailored to fit the characteristics of medical images [78], including dimension discrepancy [89], structure similarity [43], etc.
Among these methods, we select the Masked Autoencoder (MAE) [31] as our self-supervised pre-training strategy for three reasons: (1) the computation of CL is infeasible given the input size of SAM, i.e. ; (2) SAM also utilized an MAE pre-trained vision transformer as the initial model; (3) there is increasing evidence showing the effectiveness of using MAE during medical image segmentation [100, 101, 84]. MAE first divides input images into non-overlapping patches and removes most of them, and its goal is to reconstruct these original inputs given the remaining ones. For the same reason as in task-expansive prompt-based learning, we also conduct training with MRIs only and evaluate all datasets.
3 Dataset
We select 22 datasets from publicly available sources online, including TCIA (The Cancer Imaging Archive), Kaggle, Zendo, Grand Challenge, and Mendeley Data. Figure 3 presents a visual summary of the datasets used in this paper. In total, we collect magnetic resonance images (MRI) datasets, computed tomography (CT) datasets, ultrasound (US) datasets, and X-ray datasets. Our datasets cover images from main human anatomical locations. Examples of all datasets are also included in the same figure, in addition to the image count of each dataset, each anatomical location, and each modality. The details of each dataset are listed in Table 2, including the citation, description, number of images, and number of masks. All datasets employ expert annotated segmentation masks except for the MRI-Knee dataset, which is used exclusively for self-supervised pre-training and thus their numbers of masks are indicated as “not used”.
Since SAM is a 2D-based segmentation network, 3D volumes are first extracted to 2d slices. We convert NifTI, mha, and Dicom volumes by normalizing all pixel values to 0-255 and further upsampling each slice to using nearest-neighbor interpolation to meet SAM’s required input size. The pixel values are repeated three times across the three channels for all grayscale images. We split each dataset into training, validation, and test sets by dividing patients into splits accordingly.
In our study, we utilize this curated medical imaging datasets across various levels of data availability as follows:
- 1.
Specific Dataset Fine-tuning: This involves datasets applied for fine-tuning on a single labeled dataset, including all datasets listed in the first section of Table 2.
- 2.
Prompt-based Supervised Training with Multiple Labeled Datasets: This category includes all MRI datasets that come with available masks, utilized for supervised pre-training.
- 3.
Self-Supervised Learning with Both Labeled and Unlabeled Datasets: This level pertains to the use of all MRI datasets mentioned in our table for self-supervised learning, incorporating both labeled and unlabeled datasets.
| Model | # of param. | # of trainable param. | GPU allocated (MB) | Single iteration time (s) | ||
|---|---|---|---|---|---|---|
| ViT-H | Decoder | Vanilla | 640.95M | 3.92M (0.61%) | 22206 | 1.82 |
| Adapter | 641.08M | 0.13M (0.021%) | 17210 | 1.88 | ||
| LoRA | 640.97M | 0.65M (0.10%) | 17214 | 1.81 | ||
| En/Decoder | Vanilla | 640.95M | 640.95M (100.0%) | 99,208 | 5.2 | |
| Adapter | 650.93M | 9.98M (1.53%) | 69,144 | 3.8 | ||
| LoRA | 641.63M | 1.31M (0.20%) | 68,540 | 3.82 | ||
| ViT-B | Decoder | Vanilla | 93.60M | 3.92M (4.19%) | 11158 | 0.44 |
| Adapter | 93.73M | 0.13M (0.14%) | 11532 | 0.45 | ||
| LoRA | 93.62M | 0.65M (0.69%) | 11530 | 0.44 | ||
| En/Decoder | Vanilla | 93.60M | 93.60M (100.0%) | 37306 | 1.16 | |
| Adapter | 97.28M | 3.68M (3.79%) | 33454 | 1 | ||
| LoRA | 93.77M | 0.80M (0.86%) | 30578 | 0.95 | ||
| ViT-T | Decoder | Vanilla | 9.99M | 3.92M (39.22%) | 1404 | 0.08 |
| Adapter | 10.12M | 0.13M (1.13%) | 1398 | 0.09 | ||
| LoRA | 10.01M | 0.65M (6.49%) | 1400 | 0.08 | ||
| En/Decoder | Vanilla | 9.99M | 9.99M (100.0%) | 10102 | 0.25 | |
| Adapter | 10.31M | 0.32M (3.12%) | 4018 | 0.16 | ||
| LoRA | 10.04M | 0.79M (7.82%) | 4036 | 0.15 | ||
4 Experiment
In this section, we conduct various experiments to assess the effectiveness of fine-tuning strategies across multiple datasets and configurations. First and foremost, we analyze the behaviors of these strategies when conducting task-specific supervised training. Next, we examine the effectiveness of applying task-expansive prompt-based learning or task-agnostic self-supervised learning before task-specific supervised training. These experiments are further extended to the few-shot learning and interactive segmentation setting. Throughout the paper, we use the dice similarity score (DSC%) as the evaluation metric.
4.1 Which fine-tuning combination is the best if applying task-specific supervised training only?
4.1.1 Implementation details
When conducting task-specific supervised training, in addition to finding the most effective fine-tuning strategy, we also want to compare the performance against conventional UNet-based algorithms. Therefore, we have chosen three well-known and frequently used automated segmentation models for comparison: UNet [70], nnUNet [40], and SwinUNet [13]:
- 1.
UNet serves as the baseline of the convolutional neural network-based segmentation algorithm.
- 2.
nnUNet configures a UNet-based algorithm according to the specific attributes of the input datasets and approximates the performance of UNet with the optimal design choice.
- 3.
SwinUNet replaces the encoder of UNet with a swin-transformer [58].
For PEFT with Adapter blocks, we implemented it based on [87], which added adapter blocks to SAM’s attention blocks. In the image encoder, adapter blocks were added into transformer blocks right after the multi-attention head or within the MLP residual block with a scalable parameter [15]. In the default setting, we added Adapter blocks at the first two and last two transformer blocks (layers) in the image encoder. In the mask decoder, Adapters were added after the multi-head attention head. For PEFT with LoRA blocks, we implemented it based on SAMed [96], which inserted LoRA layers into the “query” and “value” projection layers of each transformer block in the image encoder and mask decoder.
In the pre-processing step of our datasets, we removed all data lacking target objects, specifically those images where the corresponding masks only consist of the background, for both training and testing purposes. We also followed the same normalization mean and standard deviation as the original SAM. We utilized dice loss and cross-entropy loss with equal weights. For all experiments across various datasets, we adapted a basic learning rate of 1e-4 with a warmup of iterations and applied AdamW with weight decay for the remaining iterations. The batch size was set to . Histogram equalization and color jitter were the augmentations used during training. The maximum epochs were set to epochs, incorporating an early stopping mechanism that halted training if there was no improvement in the highest validation DSC for consecutive epochs. For settings that require heavy computing resources, such as ViT-H with the vanilla setting, we adopted Distributed Data Parallel (DDP) combined with model parallel to split batches or the model into 2-3 GPUs. The specifics regarding the total number of parameters in the model, the number of parameters subject to updates for each combination, and the computing resources needed are detailed in Table 3.
4.1.2 Results
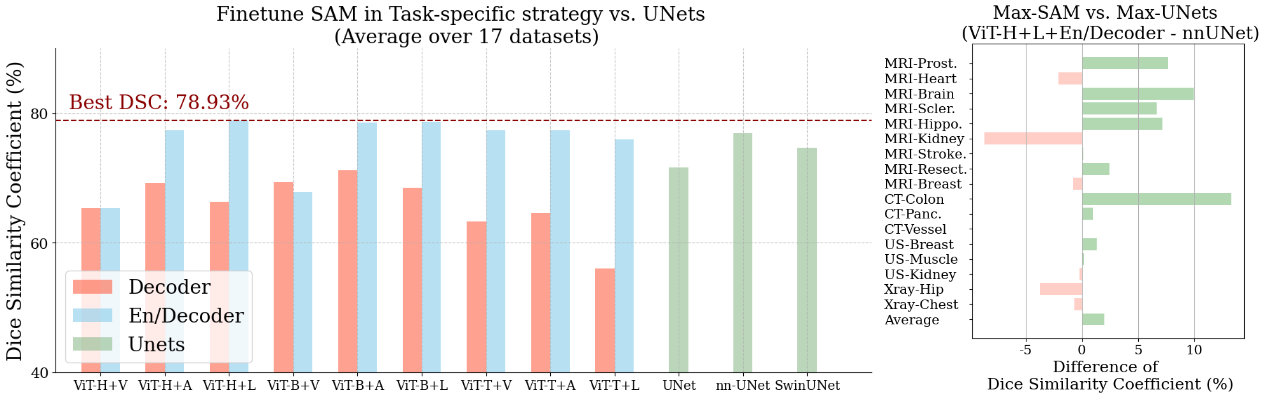
Figure 4 shows the performance of various task-specific fine-tuning approaches across each dataset and the performance of various UNet-based algorithms. The detailed results of each architecture-component-method fine-tuning strategy over 17 datasets can be found in the Appendix. Note that we provide the numerical results for all figure-based results in the Appendix. By comparing the red and blue bars, we first observe an almost definite (except in the ViT-B + Vanilla setting) improvement in the average performance when changing from only updating the decoder parameters to that of both the encoder and decoder. This discovery indicates that SAM’s original image encoder, initially trained on a vast collection of natural images, is not well-suited for efficiently extracting features from medical images, aligned with previous studies [61]. Therefore, freezing it and directly adapting the mask decoder for downstream tasks in the medical domain results in sub-optimal performance.
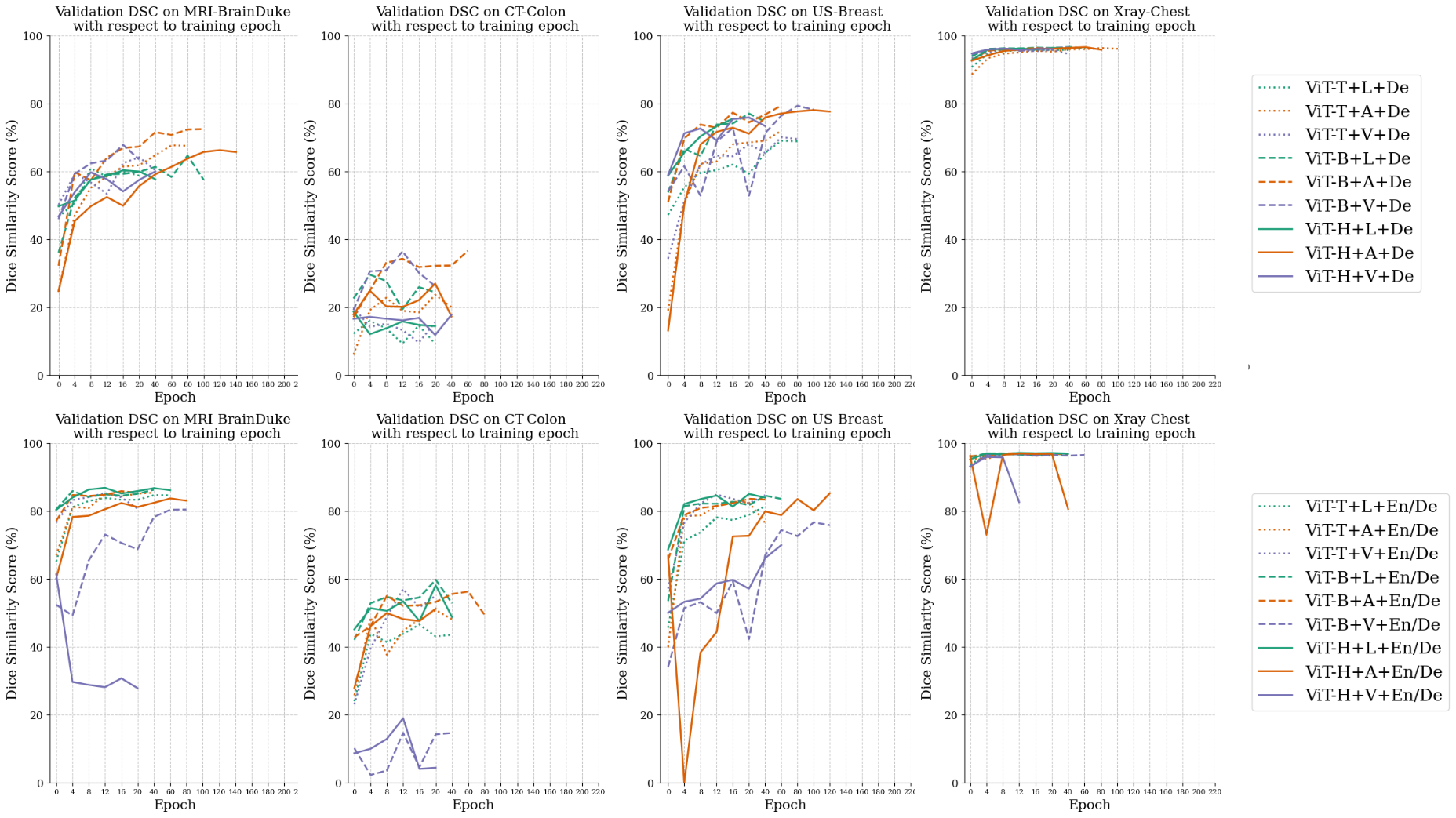
When comparing the performances among Vanilla, Aapter, and LoRA, we observe little difference between the two PEFT methods (Adapter and LoRA), and the rank between Vanilla and PEFT methods depends on the choices of backbones. When using the standard-size backbone (ViT-H or ViT-B), we observe an absolute advantage of using PEFT techniques. For example, when comparing the middle three blue bars in Figure 4, we observe using PEFT with Adapter or LoRA achieves and DSC respectively, while vanilla fine-tuning yields only DSC. We also conduct an additional study to insert the Adapter block after each layer and observe little difference. However, the difference between vanilla fine-tuning and PEFT is significantly reduced when using ViT-T, the small backbone introduced by MobileSAM [94]. We hypothesize the large gap between Vanilla and PEFT methods with a standard-size backbone is caused by the model collapse and knowledge-forgotten issues when fine-tuning all parameters of a large model [23, 26]. To support our hypothesis, we track the change of validation DSC on all datasets, and the examples of each modality are shown in Figure 5. It reveals that ViT-H + En/Decoder + Vanilla would cause a model collapse at an early stage. For instance, when applied to the MRI-BrainDuke dataset, this configuration results in a significant reduction in performance, with a decrease of approximately in DSC.
Next, our results reveal that the choice of encoder network architecture has minimal impact on performance when other choices remain the same. For instance, under the same settings of updating both encoder and decoder with Adapter (EN/Decoder + Adapter), we observe similar DSC scores across different encoders: ViT-H, ViT-B, and ViT-T. This similarity in performance occurs despite ViT-H having a significantly larger encoder with times network parameters compared with ViT-B and times parameters compared with ViT-T, as listed in Table 3. We deduce that while ViT-H excels in foundational settings for multiple segmentation tasks, it may be too parameter-rich for singular medical imaging segmentation tasks, given the typically smaller dataset sizes in the medical imaging field. Such property can also make the training difficult. As shown in Figure 5 top right, it takes epochs to train the ViT-H + En/Decoder + Adapter setting, which is approximately times longer when conducting the same setting with ViT-B, yet the latter gives slightly better performance ( DSC vs. DSC when using ViT-H and ViT-B as the backbone respectively). Given the uniform results across our 17 datasets, we deduce that using PEFT (Adapter or LoRA) to fine-tune SAM within a smaller framework offers more benefits. This strategy strikes an optimal balance between efficiency and performance, especially for medical image segmentation tasks where datasets typically range from a couple hundred to tens of thousands of images.
Lastly, when comparing the results of automated segmentation by directly training on UNets, we observe that fine-tuning SAM with the En/Decoder generally yields better average performance. To further study the optimal performance across individual datasets, we select the best SAM-based method (ViT-H+LoRA+En/Decoder) vs. the best UNet-based method (nnUNet) in Figure 4, right block. It appears that SAM excels in tasks where the objects of interest are complicated, such as MRI-Brain Sclerosis or CT-Colon. Conversely, nnUNet demonstrates higher precision in tasks with simpler targets, including Xray-Hip or MRI-Kidney.
4.2 Is task-expansive prompt-based learning helpful for further automated segmentation?
As discussed in Section 2.3, we utilize an interactive segmentation setting for task-expansive prompt-based learning. In this section, we provide the implementation details and analysis of its performance.
4.2.1 Implementation details
When implementing task-expansive prompt-based learning, we utilized a collection of datasets and their corresponding masks. Our experimental setup focused on training with all MRI datasets listed in Table 2 except “MRI-Knee”. In this collection criteria, we include 13 MRI datasets including 45k training image and non-empty mask pairs, and 7.9k evaluation images and mask pairs. We selected ViT-B as the encoder architecture since (1) it achieved similar performance to ViT-H in the data-specific fine-tuning setting; (2) MobileSAM was a distilled version of SAM which was not provided by initial SAM and thus less representative.
Under this multi-dataset supervised training setting, we configured a batch size of 3, utilizing DDP across 3 A6000 GPUs for training. The training was stopped when the validation performance was not improved for 5 epochs. To train the network, we fixed the prompt encoder and updated the image encoder and mask decoder in a vanilla setting (same as SAM’s supervised training stage). We generated a box or point prompt for each image as described in Section 2.3. Additionally, in this setting, we incorporated MedSAM [59] as a parallel approach since its training algorithm was similar to the proposed task-expansive prompt-based learning but with a different database.
In this experimental setup, our methodology follows a two-phase procedure, depicted in Figure 1 Setup 2: (1) Phase 1: task-expansive prompt-based learning. (2) Phase 2: task-specific supervised training for each dataset, beginning from pre-trained weights. We name the weights after phase 1 as SupSAM. The implementation details in the task-specific setting were identical to those of the previous section (Section 4.1). In phase 2, we had 2 model component choices (En/Decoder or Decoder only) and 3 Vanilla/PEFT choices in the automated setting. We evaluated the final automated segmentation performance after phase 2.
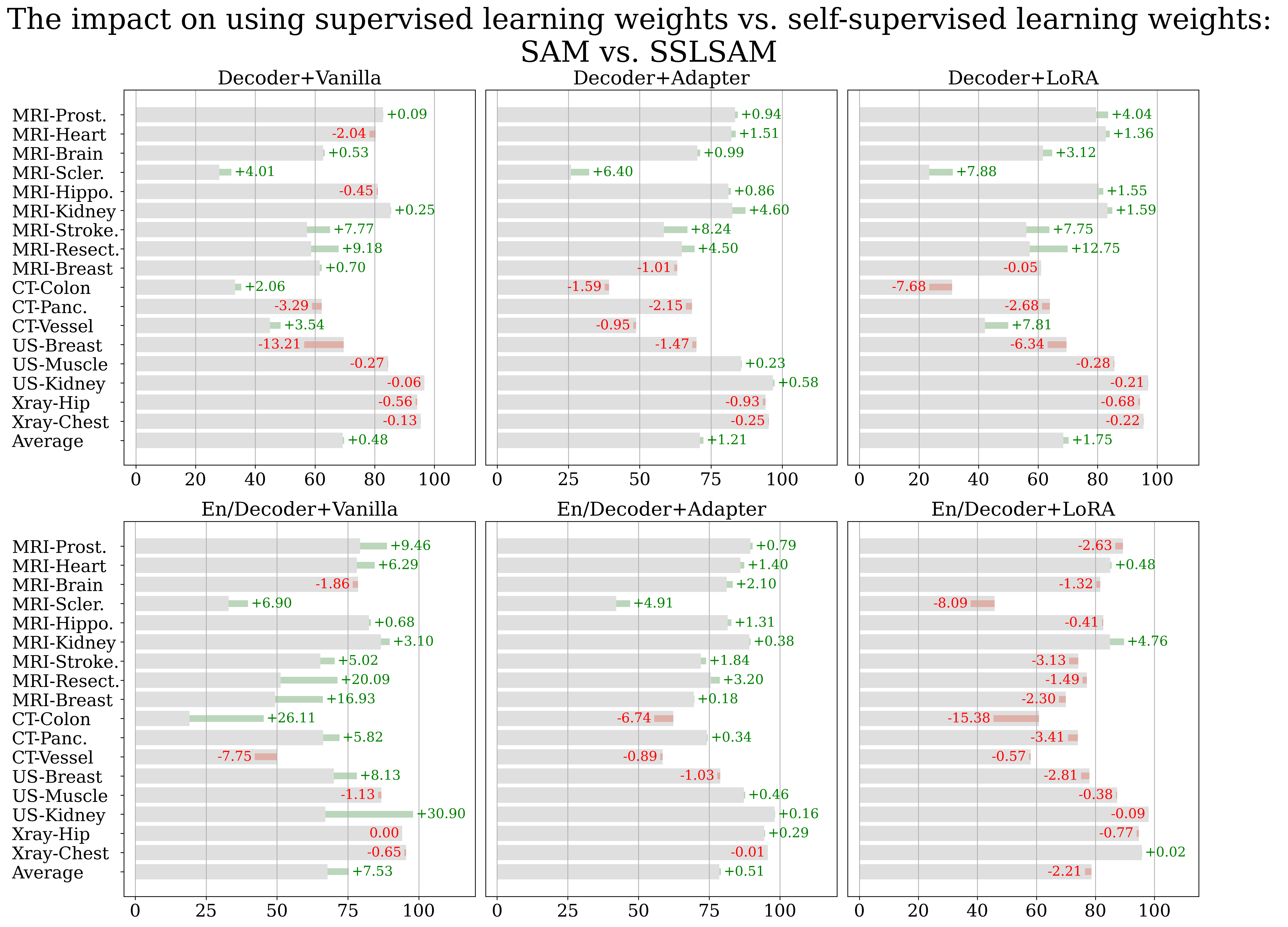
4.2.2 Results
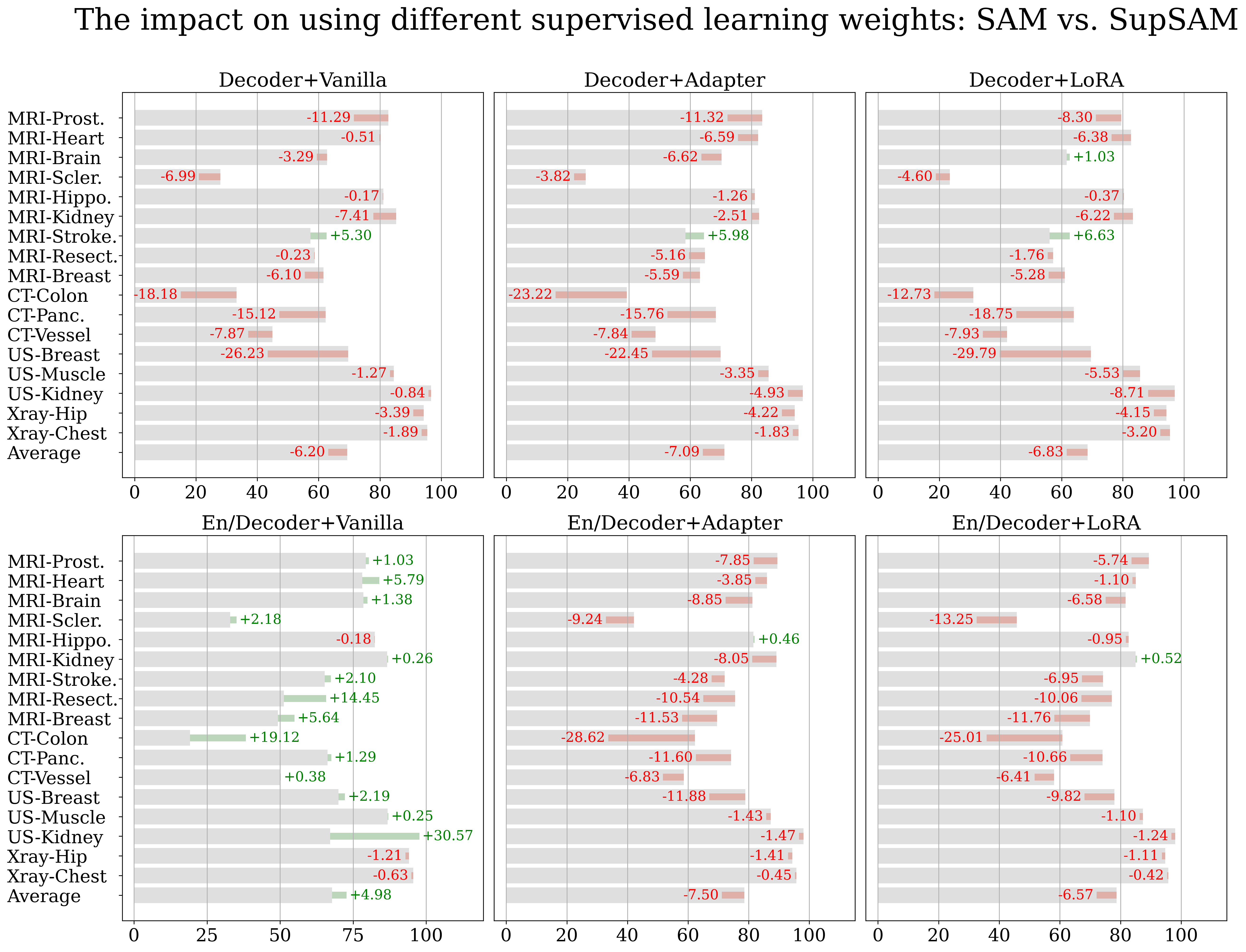
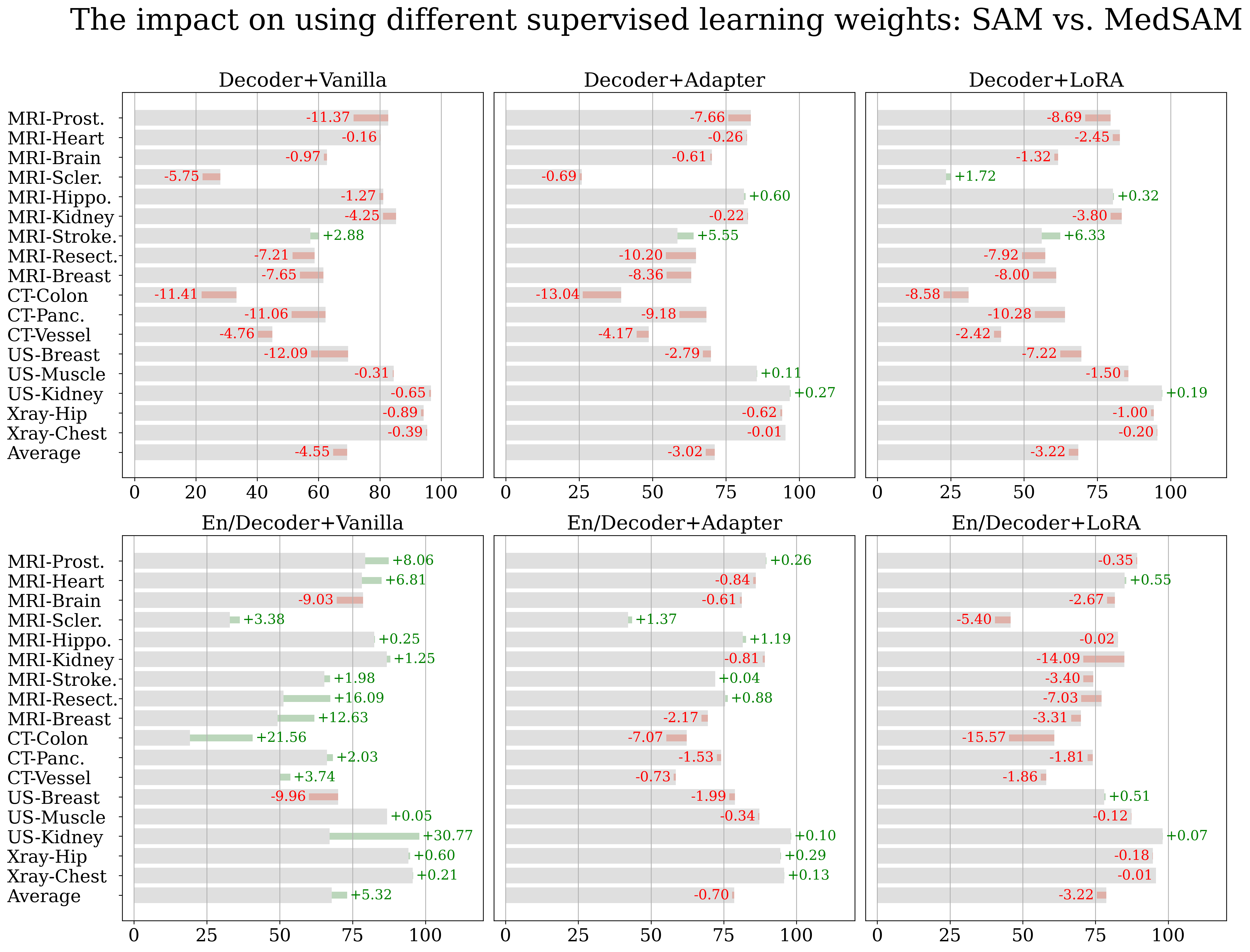
The results are shown in Figure 6 and Figure 7, in which we list the performance of the original method when starting from SAM’s initial weights in gray. We further illustrate the difference, highlighted in green (when positive) or red (if negative), when changing the initial weights from the original SAM to those acquired from task-expansive prompt-based learning or MedSAM, respectively. When task-specific supervised training is applied solely to the decoder (the upper 3 blocks in both figures), we observe a consistent performance decrease in both scenarios. Since in this case, phase 2 fine-tuning is applied exclusively to the decoder, it appears that weights learning through supervised training fail to adequately prepare the image encoder with the medical imaging domain knowledge necessary for automated feature extraction. Thus, attempting to conserve computational resources while starting with a publicly available, prompt-based medical model, such as MedSAM, becomes unnecessary if the goal is to update only the small decoder for customized datasets.
When fine-tuning both the encoder and decoder during phase 2 task-specific supervised training (Figure 6 and 7, bottom 3 blocks), we observe either a negative or no effect when utilizing a different pre-trained weights when using PEFT methods and a positive effect when using Vanilla fine-tuning. However, the latter setting leads to worse overall performance and thus offers little practical value. Despite the decrement being alleviated when using MedSAM, the overall trend shows the ineffectiveness of prompt-based learning when the ultimate goal is automated segmentation (MedSAM has around 34 times larger training set yet results in no performance change at best). We infer that the observed performance enhancement in En/Decoder-Vanilla is attributed to supervised pre-training potentially nudging the weights closer to the medical domain, thereby reducing the likelihood of model collapse. Nonetheless, given that this configuration still results in the lowest segmentation performance compared to the PEFT setting, this improvement does not offer practical benefit.
Our research indicates that supervised pre-training across various labeled medical images, despite working well in the original setting (MedSAM [59] is verified in its paper and ours is verified in Section 4.2), fails to enhance automated segmentation performance. We believe the ineffectiveness of additional supervised pre-training is due to the difference in the tasks: (1) The weights learned from interactive (prompt-based) mode vs. automated mode might be different and could not commute with each other effectively. Additionally, extended pre-training might disrupt the original weights’ transferability. (2) Furthermore, training the network on multiple segmentation tasks simultaneously could lead to conflicts within the training process thus making the training more challenging.
4.3 Is task-agnostic self-supervised learning helpful for further automated segmentation?
As discussed in Section 2.4, we select masked autoencoder (MAE) as the method for task-agnostic self-supervised learning. In this section, we provide the implementation details and analyze its performance.
4.3.1 Implementation details
In this stage, all MRI datasets in Table 2 were used during training. The mask information was ignored and only the images from the training set were utilized. Blank slices were further removed since they were not informative for the reconstruction task. This resulted in images for training.
Following the previous section, we only select ViT-B as the encoder architecture. To employ MAE’s objective, we introduced an additional decoder to reconstruct the inputs, which was discarded after training. The additional decoder’s structure, mask ratio, and learning rate schedule all follow that of the original paper. Since the shape of SAM’s input was restricted to , we set the batch size to . To accommodate for the small batch size, we set the accumulative iteration, i.e. the number of iterations to only compute gradients without updating the network parameters, to . The training was conducted on 8 A6000 for epochs.
In this experimental setup, our methodology follows a similar two-phase procedure: (1) Phase 1: task-agnostic self-supervised learning. (2) Phase 2: task-specific supervised training for each dataset, beginning from pre-trained weights. We name the weights after phase 1 as SSLSAM, which is shared publicly at https://github.com/mazurowski-lab/finetune-SAM.
4.3.2 Results
Figure 8 presents the results of using SSLSAM as the weights before task-specific supervised training. We observe an improvement in the average performance of all MRIs across all architecture combinations besides En/Decoder + LoRA. Noticeably, when selecting En/Decoder + Adapter as the fine-tuning strategy, we observe consistent improvements over all MRI datasets, and the model achieves an average performance of , which surpasses the leading ViT-H based method by and the best UNet-based method (nnUNet) by . Contradictory to task-expansive prompt-based learning, the features learned during SSL are task agnostic, and since we only pre-train the encoder, there is no dependence on the task condition, which we have shown to hurt the performance. In the non-MRI datasets base, we observe a minor decrease in the performance. This can be due to the specificity of the MRI.
4.4 Which fine-tuning setup works the best in the few-shot learning setting?
4.4.1 Implementation details
One of the popular scenarios for adopting fine-tuning strategies is when the target dataset has a limited number of annotated images, known as few-shot fine-tuning. Few-shot fine-tuning gets even more attention in the field of medical imaging segmentation, given the difficulty in securing a substantial quantity of expert annotations. We explore the effectiveness of different fine-tuning procedures under the following setting.
Our study primarily investigates 5-shot learning, selecting five images and their corresponding annotations randomly from the training set and validation set respectively. In the case of datasets derived from 3D volumes, these samples were chosen from distinct volumes to ensure diversity. In addition to the constraint of using only 5 training/validation images, we also modified the training hyper-parameters better suited for the few-shot setting. Specifically, we set a maximum of 1000 epochs for training, a batch size of 2, and did not include any early stopping criteria.
In this setting, we also investigated the previous three setups within a few-shot framework, including (1) task-specific fine-tuning exclusively, and (2) two pre-trained setups: task-expansive prompt-based learning and task-agnostic self-supervised learning, each followed by additional task-specific fine-tuning. To note, we cannot utilize the weights learned from task-expansive prompt-based learning since its training pipeline requires all labeled images. Thus, we consider the weights from MedSAM as an alternative. In this section, we investigate three key questions: (1) whether additional pre-training offers superior initial weights for the few-shot setting, (2) which fine-tuning strategy proves most effective in a few-shot context, (3) whether fine-tuning foundation models still work better than UNets in the few-shot setting?
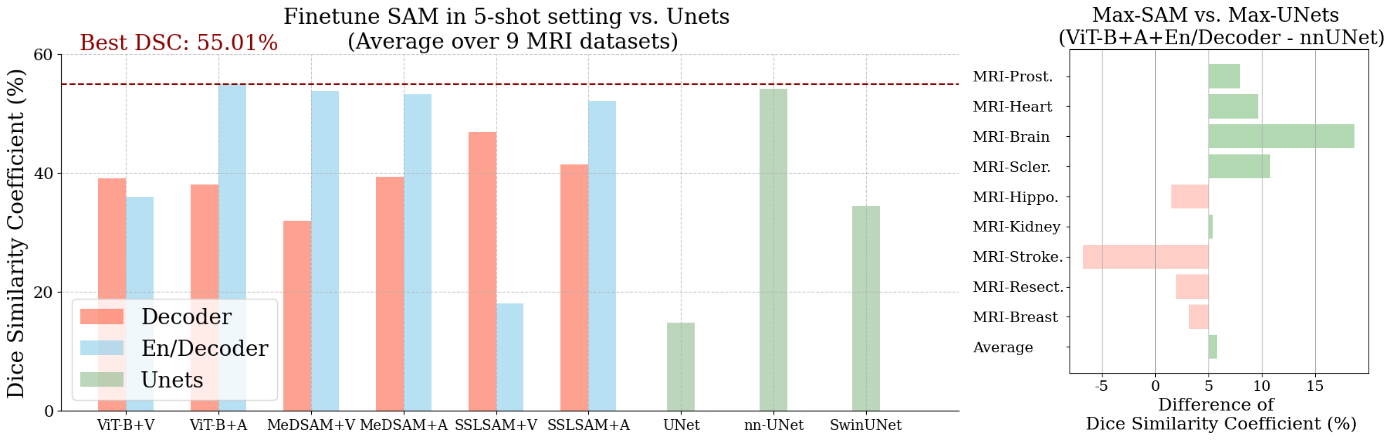
4.4.2 Results
Figure 9 shows the results for 5-shot setting, comparing the fine-tuning of SAM’s models with direct training on UNets. The results demonstrate that using ViT-B + En/Decoder + Adapter on the initial SAM yields optimal performance across all configurations. Comparing the results with UNets’, especially with the best-performing nnUNet, fine-tuned SAM still manages to achieve a slight improvement. This observation aligns with the findings presented in Section 4.1.
Consistently, the observation that MedSAM is ineffective persists in this few-shot scenario. While SSLSAM has shown effectiveness in the full-dataset setting, its efficacy diminished and even became detrimental in the few-shot scenario. This observation aligns with the understanding that the task-agnostic training disrupts the model’s connection with the segmentation tasks. While beneficial as initial weights for full-dataset training, this approach may not adequately rebuild these connections with only five images, resulting in lower performance. In summary, we observe the ineffectiveness of additional pre-training (either using task-expansive prompt-based learning or task-agnostic self-supervised learning) with limited training data. This can be contradictory to the common belief that imposing medical knowledge to the network in advance will be beneficial in the few-shot learning scenario.
4.5 What if I can provide prompts to SAM?
Despite the primary goal of this paper is to find the best practice to build an automated segmentation algorithm from the foundation models, we conduct a non-trivial extension that studies the effectiveness of various task-specific supervised training strategies in the interactive segmentation setting.
4.5.1 Implementation details
We considered two types of prompts: point or box. To generate a prompt, we utilized the same strategy as in task-expansive prompt-based learning. The generated prompts were fed to the prompt encoder to obtain the prompt embeddings during both training and inference. The prompt encoder was fixed. We also limited the evaluation data to MRI only since this task was not our main focus.
We included the performance of applying prompts to the original SAM and its oracle performance; the latter reflects the hypothetical performance when conducting an extra step to determine the best prediction from the network. Additionally, we include weights acquired from task-expansive prompt-based learning and MedSAM in the box-prompt setting. When applying task-specific supervised training to SAM, we followed Section 4.1 to include all strategies.
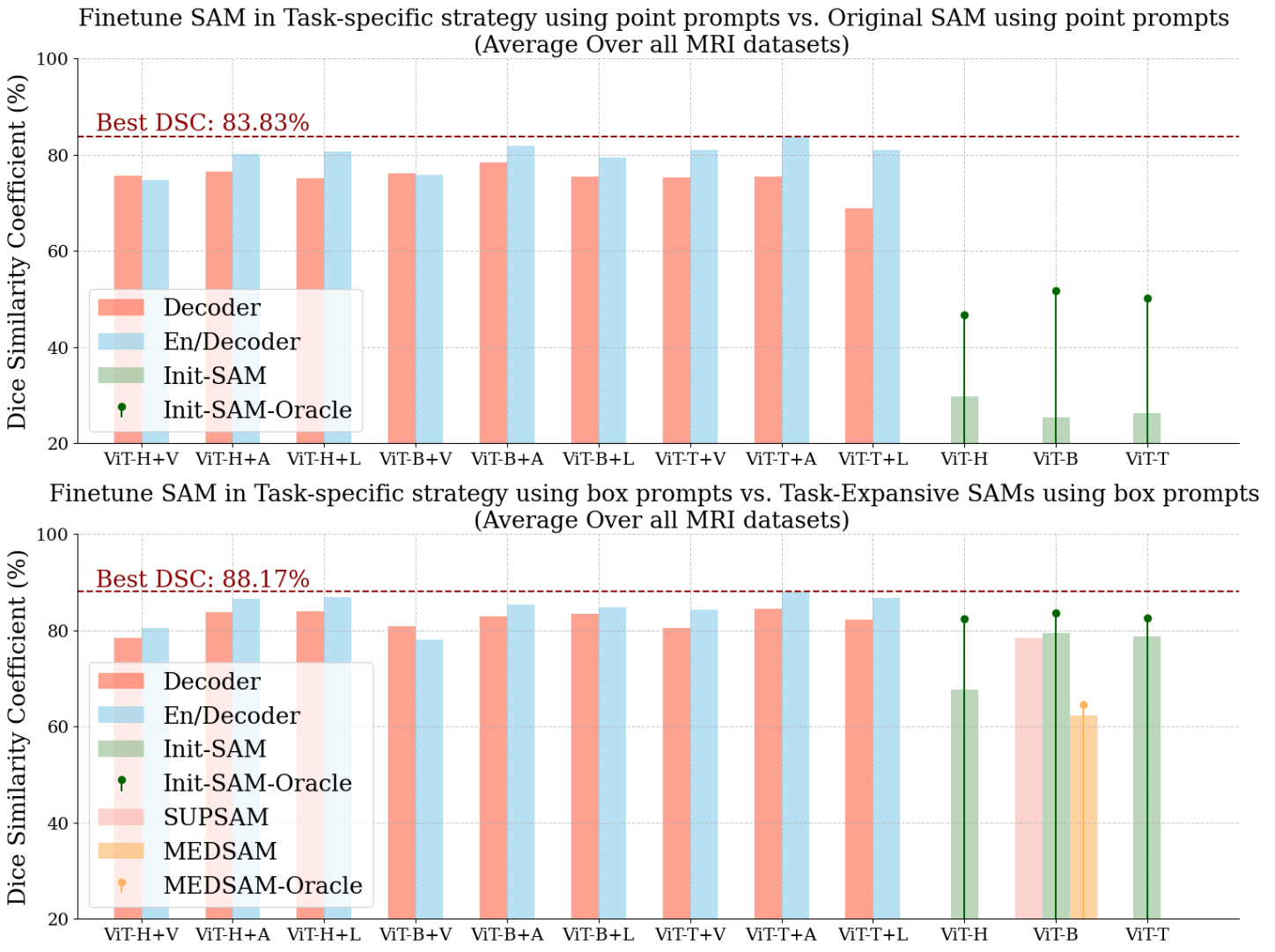
4.5.2 Results
Figure 10 shows the performance of all task-specific supervised training strategies in the interactive mode, as well as that of the original SAM as a reference. First, we observe the performance of SAM with point prompts is not satisfying. Replacing the point prompts with box ones significantly improves the performance. In this setting, we also examine the weights acquired from task-expansive prompt-based learning and observe similar performance (less than DSC difference compared to that of the initial SAM). This observation confirms that the inefficiency of task-expansive prompt-based learning is inherently from having different tasks in mind.
To be noted, the best automated task-specific supervised training strategy yields an average performance of on all MRI datasets, which is better than the original SAM with point prompts and on par with that with box prompts.
Conducting task-specific supervised training is also shown to be effective in the interactive segmentation scenario, especially when points are used as the prompts. Moreover, we find the best task-specific supervised training strategy is ViT-T + En/Decoder + Adapter in both scenarios, achieving DSC when using a point/box as the prompt.
5 Conclusion
In summary, we systematically study different strategies to fine-tune the Segment Anything Model (SAM) in the medical imaging field. Our extensive experiments reveal several interesting observations and provide a guideline for developing an automated segmentation algorithm from SAM. Our findings are based on dataset availability, and are summarized as follows:
When only a single dataset is available for fine-tuning, we find that:
- 1.
Fine-tuning SAM, if with proper strategies, leads to better segmentation performance than training from scratch with nnUNet [40].
- 2.
Increasing the size of network architecture leads to a marginal increase in segmentation performance while exponentially longer training time.
- 3.
Using parameter-efficient fine-tuning (PEFT) techniques has a clear advantage over fine-tuning all parameters on medium-to-large-size architectures (ViT-H or ViT-B) but not on the small architecture (ViT-T).
- 4.
Optimizing both the encoder and decoder (En/De) has clear advantages over only the decoder, with the latter being a popular choice in the literature.
- 5.
In summary, we recommend using ViT-B + En/Decoder + PEFT as the fine-tuning framework because of its leading performance and moderate computation cost.
When having multiple datasets, we can incorporate general medical knowledge into SAM through additional pre-training, and find that:
- 1.
Using additional labeled data for other tasks with prompt-based learning is an inefficient strategy to further improve SAM’s performance.
- 2.
Using additional unlabeled data with self-supervised learning can improve SAM’s performance when the test data is from the same modality as the pre-trained data and has no effect otherwise.
When we adjust the fine-tuning task into few-shot learning, we find that:
- 1.
Fine-tuning SAM significantly outperforms UNet, and still maintains a slight improvement compared with nn-UNet in the 5-shot setting.
- 2.
Additional task-expansive prompt-based learning or task-agnostic self-supervised learning do not contribute to improvements in the final few-shot learning task.
Lastly, in the interactive segmentation scenario, we observe that:
- 1.
Fine-tuned SAM brings substantial performance improvements compared to SAM and MedSAM in the interactive segmentation setting.
- 2.
Our recommendation framework is ViT-T + En/Decoder + PEFT given its superior performance and low computation cost.
References
- [1] Mugahed A Al-Antari, Mohammed A Al-Masni, Mun-Taek Choi, Seung-Moo Han, and Tae-Seong Kim. A fully integrated computer-aided diagnosis system for digital x-ray mammograms via deep learning detection, segmentation, and classification. International journal of medical informatics, 117:44–54, 2018.
- [2] Walid Al-Dhabyani, Mohammed Gomaa, Hussien Khaled, and Fahmy Aly. Deep learning approaches for data augmentation and classification of breast masses using ultrasound images. Int. J. Adv. Comput. Sci. Appl, 10(5):1–11, 2019.
- [3] Max Allan, Satoshi Kondo, Sebastian Bodenstedt, Stefan Leger, Rahim Kadkhodamohammadi, Imanol Luengo, Felix Fuentes, Evangello Flouty, Ahmed Mohammed, Marius Pedersen, et al. 2018 robotic scene segmentation challenge. arXiv preprint arXiv:2001.11190, 2020.
- [4] Michela Antonelli, Annika Reinke, Spyridon Bakas, Keyvan Farahani, Annette Kopp-Schneider, Bennett A Landman, Geert Litjens, Bjoern Menze, Olaf Ronneberger, Ronald M Summers, et al. The medical segmentation decathlon. Nature communications, 13(1):4128, 2022.
- [5] Samuel G Armato III, Henkjan Huisman, Karen Drukker, Lubomir Hadjiiski, Justin S Kirby, Nicholas Petrick, George Redmond, Maryellen L Giger, Kenny Cha, Artem Mamonov, et al. Prostatex challenges for computerized classification of prostate lesions from multiparametric magnetic resonance images. Journal of Medical Imaging, 5(4):044501–044501, 2018.
- [6] Shekoofeh Azizi, Laura Culp, Jan Freyberg, Basil Mustafa, Sebastien Baur, Simon Kornblith, Ting Chen, Patricia MacWilliams, S Sara Mahdavi, Ellery Wulczyn, et al. Robust and efficient medical imaging with self-supervision. arXiv preprint arXiv:2205.09723, 2022.
- [7] Samyadeep Basu, Daniela Massiceti, Shell Xu Hu, and Soheil Feizi. Strong baselines for parameter efficient few-shot fine-tuning. arXiv preprint arXiv:2304.01917, 2023.
- [8] Olivier Bernard, Alain Lalande, Clement Zotti, Frederick Cervenansky, Xin Yang, Pheng-Ann Heng, Irem Cetin, Karim Lekadir, Oscar Camara, Miguel Angel Gonzalez Ballester, et al. Deep learning techniques for automatic mri cardiac multi-structures segmentation and diagnosis: is the problem solved? IEEE transactions on medical imaging, 37(11):2514–2525, 2018.
- [9] Nicholas Bien, Pranav Rajpurkar, Robyn L Ball, Jeremy Irvin, Allison Park, Erik Jones, Michael Bereket, Bhavik N Patel, Kristen W Yeom, Katie Shpanskaya, et al. Deep-learning-assisted diagnosis for knee magnetic resonance imaging: development and retrospective validation of mrnet. PLoS medicine, 15(11):e1002699, 2018.
- [10] Mateusz Buda. Brain mri segmentation: Brain mri images together with manual flair abnormality segmentation masks. Kaggle, 2019.
- [11] Nhat-Tan Bui, Dinh-Hieu Hoang, Minh-Triet Tran, and Ngan Le. Sam3d: Segment anything model in volumetric medical images. arXiv preprint arXiv:2309.03493, 2023.
- [12] Han Cai, Chuang Gan, Ligeng Zhu, and Song Han. Tinytl: Reduce memory, not parameters for efficient on-device learning. Advances in Neural Information Processing Systems, 33:11285–11297, 2020.
- [13] Hu Cao, Yueyue Wang, Joy Chen, Dongsheng Jiang, Xiaopeng Zhang, Qi Tian, and Manning Wang. Swin-unet: Unet-like pure transformer for medical image segmentation. In European conference on computer vision, pages 205–218. Springer, 2022.
- [14] Cheng Chen, Juzheng Miao, Dufan Wu, Zhiling Yan, Sekeun Kim, Jiang Hu, Aoxiao Zhong, Zhengliang Liu, Lichao Sun, Xiang Li, et al. Ma-sam: Modality-agnostic sam adaptation for 3d medical image segmentation. arXiv preprint arXiv:2309.08842, 2023.
- [15] Shoufa Chen, Chongjian Ge, Zhan Tong, Jiangliu Wang, Yibing Song, Jue Wang, and Ping Luo. Adaptformer: Adapting vision transformers for scalable visual recognition. Advances in Neural Information Processing Systems, 35:16664–16678, 2022.
- [16] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. In Hal Daumé III and Aarti Singh, editors, Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 1597–1607. PMLR, 13–18 Jul 2020.
- [17] Tianrun Chen, Lanyun Zhu, Chaotao Ding, Runlong Cao, Shangzhan Zhang, Yan Wang, Zejian Li, Lingyun Sun, Papa Mao, and Ying Zang. Sam fails to segment anything?–sam-adapter: Adapting sam in underperformed scenes: Camouflage, shadow, and more. arXiv preprint arXiv:2304.09148, 2023.
- [18] Junlong Cheng, Jin Ye, Zhongying Deng, Jianpin Chen, Tianbin Li, Haoyu Wang, Yanzhou Su, Ziyan Huang, Jilong Chen, Lei Jiang, et al. Sam-med2d. arXiv preprint arXiv:2308.16184, 2023.
- [19] Can Cui, Ruining Deng, Quan Liu, Tianyuan Yao, Shunxing Bao, Lucas W Remedios, Yucheng Tang, and Yuankai Huo. All-in-sam: from weak annotation to pixel-wise nuclei segmentation with prompt-based finetuning. arXiv preprint arXiv:2307.00290, 2023.
- [20] Alexander J Daniel, Charlotte E Buchanan, Thomas Allcock, Daniel Scerri, Eleanor F Cox, Benjamin L Prestwich, and Susan T Francis. Automated renal segmentation in healthy and chronic kidney disease subjects using a convolutional neural network. Magnetic resonance in medicine, 86(2):1125–1136, 2021.
- [21] Ruining Deng, Can Cui, Quan Liu, Tianyuan Yao, Lucas W. Remedios, Shunxing Bao, Bennett A. Landman, Lee Wheless, Lori A. Coburn, Keith T. Wilson, Yaohong Wang, Shilin Zhao, Agnes B. Fogo, Haichun Yang, Yucheng Tang, and Yuankai Huo. Segment anything model (sam) for digital pathology: Assess zero-shot segmentation on whole slide imaging. ArXiv, abs/2304.04155, 2023.
- [22] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
- [23] Raman Dutt, Linus Ericsson, Pedro Sanchez, Sotirios A Tsaftaris, and Timothy Hospedales. Parameter-efficient fine-tuning for medical image analysis: The missed opportunity. arXiv preprint arXiv:2305.08252, 2023.
- [24] Xi Fang and Pingkun Yan. Multi-organ segmentation over partially labeled datasets with multi-scale feature abstraction. IEEE Transactions on Medical Imaging, 39(11):3619–3629, 2020.
- [25] Weijia Feng, Lingting Zhu, and Lequan Yu. Cheap lunch for medical image segmentation by fine-tuning sam on few exemplars. arXiv preprint arXiv:2308.14133, 2023.
- [26] Zihao Fu, Haoran Yang, Anthony Man-Cho So, Wai Lam, Lidong Bing, and Nigel Collier. On the effectiveness of parameter-efficient fine-tuning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 12799–12807, 2023.
- [27] Yifan Gao, Wei Xia, Dingdu Hu, and Xin Gao. Desam: Decoupling segment anything model for generalizable medical image segmentation. arXiv preprint arXiv:2306.00499, 2023.
- [28] Shizhan Gong, Yuan Zhong, Wenao Ma, Jinpeng Li, Zhao Wang, Jingyang Zhang, Pheng-Ann Heng, and Qi Dou. 3dsam-adapter: Holistic adaptation of sam from 2d to 3d for promptable medical image segmentation. arXiv preprint arXiv:2306.13465, 2023.
- [29] Hanxue Gu, Roy Colglazier, Haoyu Dong, Jikai Zhang, Yaqian Chen, Zafer Yildiz, Yuwen Chen, Lin Li, Jichen Yang, Jay Willhite, Alex M. Meyer, Brian Guo, Yashvi Atul Shah, Emily Luo, Shipra Rajput, Sally Kuehn, Clark Bulleit, Kevin A. Wu, Jisoo Lee, Brandon Ramirez, Darui Lu, Jay M. Levin, and Maciej A. Mazurowski. Segmentanybone: A universal model that segments any bone at any location on mri, 2024.
- [30] Daniel Gut. X-ray images of the hip joints. 1, July 2021. Publisher: Mendeley Data.
- [31] Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000–16009, 2022.
- [32] Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross B. Girshick. Momentum contrast for unsupervised visual representation learning. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9726–9735, 2020.
- [33] Moritz R Hernandez Petzsche, Ezequiel de la Rosa, Uta Hanning, Roland Wiest, Waldo Valenzuela, Mauricio Reyes, Maria Meyer, Sook-Lei Liew, Florian Kofler, Ivan Ezhov, et al. Isles 2022: A multi-center magnetic resonance imaging stroke lesion segmentation dataset. Scientific data, 9(1):762, 2022.
- [34] Fabian Hörst, Moritz Rempe, Lukas Heine, Constantin Seibold, Julius Keyl, Giulia Baldini, Selma Ugurel, Jens Siveke, Barbara Grünwald, Jan Egger, et al. Cellvit: Vision transformers for precise cell segmentation and classification. arXiv preprint arXiv:2306.15350, 2023.
- [35] Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for nlp. In International Conference on Machine Learning, pages 2790–2799. PMLR, 2019.
- [36] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021.
- [37] Mingzhe Hu, Yuheng Li, and Xiaofeng Yang. Skinsam: Empowering skin cancer segmentation with segment anything model. arXiv preprint arXiv:2304.13973, 2023.
- [38] Xinrong Hu, Xiaowei Xu, and Yiyu Shi. How to efficiently adapt large segmentation model (sam) to medical images. arXiv preprint arXiv:2306.13731, 2023.
- [39] Yuhao Huang, Xin Yang, Lian Liu, Han Zhou, Ao Chang, Xinrui Zhou, Rusi Chen, Junxuan Yu, Jiongquan Chen, Chaoyu Chen, et al. Segment anything model for medical images? Medical Image Analysis, 92:103061, 2024.
- [40] Fabian Isensee, Paul F Jaeger, Simon AA Kohl, Jens Petersen, and Klaus H Maier-Hein. nnu-net: a self-configuring method for deep learning-based biomedical image segmentation. Nature methods, 18(2):203–211, 2021.
- [41] Stefan Jaeger, Sema Candemir, Sameer Antani, Yì-Xiáng J Wáng, Pu-Xuan Lu, and George Thoma. Two public chest x-ray datasets for computer-aided screening of pulmonary diseases. Quantitative imaging in medicine and surgery, 4(6):475, 2014.
- [42] Debesh Jha, Pia H Smedsrud, Michael A Riegler, Pål Halvorsen, Thomas de Lange, Dag Johansen, and Håvard D Johansen. Kvasir-seg: A segmented polyp dataset. In MultiMedia Modeling: 26th International Conference, MMM 2020, Daejeon, South Korea, January 5–8, 2020, Proceedings, Part II 26, pages 451–462. Springer, 2020.
- [43] Yankai Jiang, Mingze Sun, Heng Guo, Xiaoyu Bai, Ke Yan, Le Lu, and Minfeng Xu. Anatomical invariance modeling and semantic alignment for self-supervised learning in 3d medical image analysis. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15859–15869, 2023.
- [44] A Emre Kavur, N Sinem Gezer, Mustafa Barış, Sinem Aslan, Pierre-Henri Conze, Vladimir Groza, Duc Duy Pham, Soumick Chatterjee, Philipp Ernst, Savaş Özkan, et al. Chaos challenge-combined (ct-mr) healthy abdominal organ segmentation. Medical Image Analysis, 69:101950, 2021.
- [45] Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. arXiv preprint arXiv:2304.02643, 2023.
- [46] Nicholas Konz and Maciej A Mazurowski. The effect of intrinsic dataset properties on generalization: Unraveling learning differences between natural and medical images. In The Twelfth International Conference on Learning Representations (ICLR), 2024.
- [47] Neeraj Kumar, Ruchika Verma, Deepak Anand, Yanning Zhou, Omer Fahri Onder, Efstratios Tsougenis, Hao Chen, Pheng-Ann Heng, Jiahui Li, Zhiqiang Hu, et al. A multi-organ nucleus segmentation challenge. IEEE transactions on medical imaging, 39(5):1380–1391, 2019.
- [48] Bennett Landman, Zhoubing Xu, J Igelsias, Martin Styner, T Langerak, and Arno Klein. Miccai multi-atlas labeling beyond the cranial vault–workshop and challenge. In Proc. MICCAI Multi-Atlas Labeling Beyond Cranial Vault—Workshop Challenge, volume 5, page 12, 2015.
- [49] Ho Hin Lee, Yu Gu, Theodore Zhao, Yanbo Xu, Jianwei Yang, Naoto Usuyama, Cliff Wong, Mu Wei, Bennett A Landman, Yuankai Huo, et al. Foundation models for biomedical image segmentation: A survey. arXiv preprint arXiv:2401.07654, 2024.
- [50] Guillaume Lemaitre, Robert Martí Marly, and Fabrice Meriaudeau. Original multi-parametric mri images of prostate. 2016.
- [51] Tianang Leng, Yiming Zhang, Kun Han, and Xiaohui Xie. Self-sampling meta sam: Enhancing few-shot medical image segmentation with meta-learning. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 7925–7935, 2024.
- [52] Christopher O Lew, Majid Harouni, Ella R Kirksey, Elianne J Kang, Haoyu Dong, Han Gu, Lars J Grimm, Ruth Walsh, Dorothy A Lowell, and Maciej A. Mazurowski. A publicly available deep learning model and dataset for segmentation of breast, fibroglandular tissue, and vessels in breast mri. Scientific reports, 14 1:5383, 2024.
- [53] Chengyin Li, Prashant Khanduri, Yao Qiang, Rafi Ibn Sultan, Indrin Chetty, and Dongxiao Zhu. Auto-prompting sam for mobile friendly 3d medical image segmentation. arXiv preprint arXiv:2308.14936, 2023.
- [54] Wei-Hong Li, Xialei Liu, and Hakan Bilen. Cross-domain few-shot learning with task-specific adapters. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7161–7170, 2022.
- [55] Yuheng Li, Mingzhe Hu, and Xiaofeng Yang. Polyp-sam: Transfer sam for polyp segmentation. arXiv preprint arXiv:2305.00293, 2023.
- [56] Xian Lin, Yangyang Xiang, Li Zhang, Xin Yang, Zengqiang Yan, and Li Yu. Samus: Adapting segment anything model for clinically-friendly and generalizable ultrasound image segmentation. arXiv preprint arXiv:2309.06824, 2023.
- [57] Caixia Liu and Mingyong Pang. Extracting lungs from ct images via deep convolutional neural network based segmentation and two-pass contour refinement. Journal of Digital Imaging, 33:1465–1478, 2020.
- [58] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021.
- [59] Jun Ma, Yuting He, Feifei Li, Lin Han, Chenyu You, and Bo Wang. Segment anything in medical images. Nature Communications, 15:1–9, 2024.
- [60] Francesco Marzola, Nens van Alfen, Jonne Doorduin, and Kristen M Meiburger. Deep learning segmentation of transverse musculoskeletal ultrasound images for neuromuscular disease assessment. Computers in Biology and Medicine, 135:104623, 2021.
- [61] Maciej A Mazurowski, Haoyu Dong, Hanxue Gu, Jichen Yang, Nicholas Konz, and Yixin Zhang. Segment anything model for medical image analysis: an experimental study. Medical Image Analysis, 89:102918, 2023.
- [62] Bjoern H Menze, Andras Jakab, Stefan Bauer, Jayashree Kalpathy-Cramer, Keyvan Farahani, Justin Kirby, Yuliya Burren, Nicole Porz, Johannes Slotboom, Roland Wiest, et al. The multimodal brain tumor image segmentation benchmark (brats). IEEE transactions on medical imaging, 34(10):1993–2024, 2014.
- [63] Ali M Muslim, Syamsiah Mashohor, Gheyath Al Gawwam, Rozi Mahmud, Marsyita binti Hanafi, Osama Alnuaimi, Raad Josephine, and Abdullah Dhaifallah Almutairi. Brain mri dataset of multiple sclerosis with consensus manual lesion segmentation and patient meta information. Data in Brief, 42:108139, 2022.
- [64] Jay N Paranjape, Nithin Gopalakrishnan Nair, Shameema Sikder, S Swaroop Vedula, and Vishal M Patel. Adaptivesam: Towards efficient tuning of sam for surgical scene segmentation. arXiv preprint arXiv:2308.03726, 2023.
- [65] Taesung Park, Alexei A Efros, Richard Zhang, and Jun-Yan Zhu. Contrastive learning for unpaired image-to-image translation. In European Conference on Computer Vision, pages 319–345. Springer, 2020.
- [66] F Pérez-García, R Rodionov, A Alim-Marvasti, R Sparks, J Duncan, and S Ourselin. Episurg: a dataset of postoperative magnetic resonance images (mri) for quantitative analysis of resection neurosurgery for refractory epilepsy. university college london. DOI, 1(0.5522):04, 2020.
- [67] Zhongxi Qiu, Yan Hu, Heng Li, and Jiang Liu. Learnable ophthalmology sam. arXiv preprint arXiv:2304.13425, 2023.
- [68] Sylvestre-Alvise Rebuffi, Hakan Bilen, and Andrea Vedaldi. Learning multiple visual domains with residual adapters. Advances in neural information processing systems, 30, 2017.
- [69] Sylvestre-Alvise Rebuffi, Hakan Bilen, and Andrea Vedaldi. Efficient parametrization of multi-domain deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8119–8127, 2018.
- [70] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18, pages 234–241. Springer, 2015.
- [71] Ashirbani Saha, Michael R Harowicz, Lars J Grimm, Connie E Kim, Sujata V Ghate, Ruth Walsh, and Maciej A Mazurowski. A machine learning approach to radiogenomics of breast cancer: a study of 922 subjects and 529 dce-mri features. British journal of cancer, 119(4):508–516, 2018.
- [72] Tal Shaharabany, Aviad Dahan, Raja Giryes, and Lior Wolf. Autosam: Adapting sam to medical images by overloading the prompt encoder, 2023.
- [73] Peilun Shi, Jianing Qiu, Sai Mu Dalike Abaxi, Hao Wei, Frank P-W Lo, and Wu Yuan. Generalist vision foundation models for medical imaging: A case study of segment anything model on zero-shot medical segmentation. Diagnostics, 13(11):1947, 2023.
- [74] Xiaoyu Shi, Shurong Chai, Yinhao Li, Jingliang Cheng, Jie Bai, Guohua Zhao, and Yen-Wei Chen. Cross-modality attention adapter: A glioma segmentation fine-tuning method for sam using multimodal brain mr images. arXiv preprint arXiv:2307.01124, 2023.
- [75] Nahian Siddique, Sidike Paheding, Colin P Elkin, and Vijay Devabhaktuni. U-net and its variants for medical image segmentation: A review of theory and applications. Ieee Access, 9:82031–82057, 2021.
- [76] Jayanthi Sivaswamy, Alphin J Thottupattu, Raghav Mehta, R Sheelakumari, Chandrasekharan Kesavadas, et al. Sub-cortical structure segmentation database for young population. arXiv preprint arXiv:2111.01561, 2021.
- [77] Yuxin Song, Jing Zheng, Long Lei, Zhipeng Ni, Baoliang Zhao, and Ying Hu. Ct2us: Cross-modal transfer learning for kidney segmentation in ultrasound images with synthesized data. Ultrasonics, 122:106706, 2022.
- [78] Yucheng Tang, Dong Yang, Wenqi Li, Holger R Roth, Bennett Landman, Daguang Xu, Vishwesh Nath, and Ali Hatamizadeh. Self-supervised pre-training of swin transformers for 3d medical image analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20730–20740, 2022.
- [79] Hugo Touvron, Matthieu Cord, Alaaeldin El-Nouby, Jakob Verbeek, and Hervé Jégou. Three things everyone should know about vision transformers. In European Conference on Computer Vision, pages 497–515. Springer, 2022.
- [80] Philipp Tschandl, Cliff Rosendahl, and Harald Kittler. The ham10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Scientific data, 5(1):1–9, 2018.
- [81] Jasper W van der Graaf, Miranda L van Hooff, Constantinus FM Buckens, Matthieu Rutten, Job LC van Susante, Robert Jan Kroeze, Marinus de Kleuver, Bram van Ginneken, and Nikolas Lessmann. Lumbar spine segmentation in mr images: a dataset and a public benchmark. arXiv preprint arXiv:2306.12217, 2023.
- [82] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- [83] Risheng Wang, Tao Lei, Ruixia Cui, Bingtao Zhang, Hongying Meng, and Asoke K Nandi. Medical image segmentation using deep learning: A survey. IET Image Processing, 16(5):1243–1267, 2022.
- [84] Wenxuan Wang, Jing Wang, Chen Chen, Jianbo Jiao, Yuanxiu Cai, Shanshan Song, and Jiangyun Li. Fremim: Fourier transform meets masked image modeling for medical image segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 7860–7870, 2024.
- [85] Jingxi Weng, Benjamin Wildman-Tobriner, Mateusz Buda, Jichen Yang, Lisa M Ho, Brian C Allen, Wendy L Ehieli, Chad M Miller, Jikai Zhang, and Maciej A Mazurowski. Deep learning for classification of thyroid nodules on ultrasound: validation on an independent dataset. Clinical Imaging, 99:60–66, 2023.
- [86] Junde Wu, Rao Fu, Huihui Fang, Yuanpei Liu, Zhaowei Wang, Yanwu Xu, Yueming Jin, and Tal Arbel. Medical sam adapter: Adapting segment anything model for medical image segmentation. arXiv preprint arXiv:2304.12620, 2023.
- [87] Qi Wu, Yuyao Zhang, and Marawan Elbatel. Self-prompting large vision models for few-shot medical image segmentation. In MICCAI Workshop on Domain Adaptation and Representation Transfer, pages 156–167. Springer, 2023.
- [88] Weiyi Xie, Nathalie Willems, Shubham Patil, Yang Li, and Mayank Kumar. Sam fewshot finetuning for anatomical segmentation in medical images. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 3253–3261, 2024.
- [89] Yutong Xie, Jianpeng Zhang, Yong Xia, and Qi Wu. Unimiss: Universal medical self-supervised learning via breaking dimensionality barrier. In European Conference on Computer Vision, pages 558–575. Springer, 2022.
- [90] Zhenda Xie, Zheng Zhang, Yue Cao, Yutong Lin, Jianmin Bao, Zhuliang Yao, Qi Dai, and Han Hu. Simmim: A simple framework for masked image modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9653–9663, 2022.
- [91] Lingling Xu, Haoran Xie, Si-Zhao Joe Qin, Xiaohui Tao, and Fu Lee Wang. Parameter-efficient fine-tuning methods for pretrained language models: A critical review and assessment. arXiv preprint arXiv:2312.12148, 2023.
- [92] Wenxi Yue, Jing Zhang, Kun Hu, Yong Xia, Jiebo Luo, and Zhiyong Wang. Surgicalsam: Efficient class promptable surgical instrument segmentation. arXiv preprint arXiv:2308.08746, 2023.
- [93] Elad Ben Zaken, Shauli Ravfogel, and Yoav Goldberg. Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models. arXiv preprint arXiv:2106.10199, 2021.
- [94] Chaoning Zhang, Dongshen Han, Yu Qiao, Jung Uk Kim, Sung-Ho Bae, Seungkyu Lee, and Choong Seon Hong. Faster segment anything: Towards lightweight sam for mobile applications. arXiv preprint arXiv:2306.14289, 2023.
- [95] Jingwei Zhang, Ke Ma, Saarthak Kapse, Joel Saltz, Maria Vakalopoulou, Prateek Prasanna, and Dimitris Samaras. Sam-path: A segment anything model for semantic segmentation in digital pathology. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 161–170. Springer, 2023.
- [96] Kaidong Zhang and Dong Liu. Customized segment anything model for medical image segmentation. arXiv preprint arXiv:2304.13785, 2023.
- [97] Li Zhang, Youwei Liang, and Pengtao Xie. Blo-sam: Bi-level optimization based overfitting-preventing finetuning of sam. arXiv preprint arXiv:2402.16338, 2024.
- [98] Yichi Zhang and Rushi Jiao. Towards segment anything model (sam) for medical image segmentation: a survey. arXiv [Preprint], 2023.
- [99] Yichi Zhang, Zhenrong Shen, and Rushi Jiao. Segment anything model for medical image segmentation: Current applications and future directions. Computers in Biology and Medicine, page 108238, 2024.
- [100] Lei Zhou, Huidong Liu, Joseph Bae, Junjun He, Dimitris Samaras, and Prateek Prasanna. Self pre-training with masked autoencoders for medical image classification and segmentation. In 2023 IEEE 20th International Symposium on Biomedical Imaging (ISBI), pages 1–6. IEEE, 2023.
- [101] Jia-Xin Zhuang, Luyang Luo, and Hao Chen. Advancing volumetric medical image segmentation via global-local masked autoencoder. arXiv preprint arXiv:2306.08913, 2023.
6 Graphic Abstract
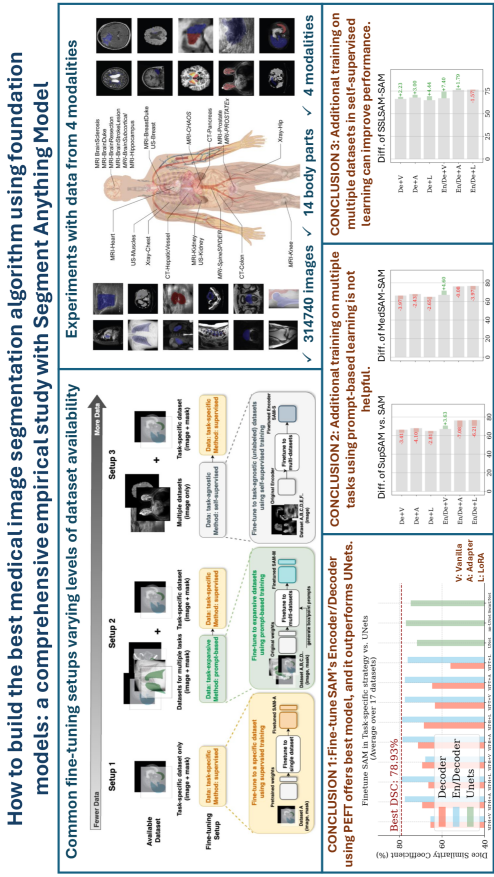
We provide a graphic abstract in Figure 11 for better understanding.
7 Appendix
In the appendix, we provide the numerical results of all experiments.
Tables 4, 5, 6 present the results of applying task-specific supervised training to ViT-H, ViT-B, and ViT-T respectively, and table 7 shows the performance of UNets. Figure 4 summarizes the results of these 4 tables.
Tables 8, 9, 10 show the performance of replacing SAM’s weights with SupSAM (acquired from task-expansive prompt-based learning), MedSAM (from [59]), and SSLSAM (acquired from task-agnostic self-supervised learning) respectively. Since all weights utilize the same encoder architecture (ViT-B), we show the difference by conducting Table 5 minus the corresponding table in Figure 6, 7, and 8 respectively.
Tables 12 and 11 show the performance of applying task-specific supervised training in the few-shot learning setting, which is summarized in Figure 9.
Tables 13 shows the performance of initial SAM in the point-based segmentation setting, with tables 14, 15, and 16 shows applying task-specific supervised training in the same setting. Tables 17, 18, 19, and 20 are conducted in the same setting but with box as the prompt. All results are summarized in Figure 10.
| Dataset | ViT-H | ||||||
|---|---|---|---|---|---|---|---|
| Decoder | En/Decoder | ||||||
| V | A | L | V | A | A* | L | |
| MRI-Prost. | |||||||
| MRI-Heart | |||||||
| MRI-Brain | |||||||
| MRI-Scler. | |||||||
| MRI-Hippo. | |||||||
| MRI-Kidney | |||||||
| MRI-Stroke. | |||||||
| MRI-Resect. | |||||||
| MRI-Breast | |||||||
| CT-Colon | |||||||
| CT-Panc. | |||||||
| CT-vessel. | |||||||
| US-Muscle | |||||||
| US-Kidney | |||||||
| Xray-Hip | |||||||
| Xray-Chest | |||||||
| Average | |||||||
| Dataset | ViT-B | |||||
|---|---|---|---|---|---|---|
| Decoder | En/Decoder | |||||
| V | A | L | V | A | L | |
| MRI-Prost. | ||||||
| MRI-Heart | ||||||
| MRI-Brain | ||||||
| MRI-Scler. | ||||||
| MRI-Hippo. | ||||||
| MRI-Kidney | ||||||
| MRI-Stroke. | ||||||
| MRI-Resect. | ||||||
| MRI-Breast | ||||||
| CT-Colon | ||||||
| CT-Panc. | ||||||
| CT-vessel. | ||||||
| US-Breast | ||||||
| US-Muscle | ||||||
| US-Kidney | ||||||
| Xray-Hip | ||||||
| Xray-Chest | ||||||
| Average | ||||||
| Dataset | ViT-B | |||||
|---|---|---|---|---|---|---|
| Decoder | En/Decoder | |||||
| V | A | L | V | A | L | |
| MRI-Prost. | ||||||
| MRI-Heart | ||||||
| MRI-Brain | ||||||
| MRI-Scler. | ||||||
| MRI-Hippo. | ||||||
| MRI-Kidney | ||||||
| MRI-Stroke. | ||||||
| MRI-Resect. | ||||||
| MRI-Breast | ||||||
| CT-Colon | ||||||
| CT-Panc. | ||||||
| CT-vessel. | ||||||
| US-Breast | ||||||
| US-Muscle | ||||||
| US-Kidney | ||||||
| Xray-Hip | ||||||
| Xray-Chest | ||||||
| Average | ||||||
| Dataset | UNet | nnUNet | SwinUNet |
|---|---|---|---|
| MRI-Prost. | |||
| MRI-Heart | |||
| MRI-Brain | |||
| MRI-Scler. | |||
| MRI-Hippo. | |||
| MRI-Kidney | |||
| MRI-Stroke. | |||
| MRI-Resect. | |||
| MRI-Breast | |||
| CT-Colon | |||
| CT-Panc. | |||
| CT-vessel. | |||
| US-Breast | |||
| US-Muscle | |||
| US-Kidney | |||
| Xray-Hip | |||
| Xray-Chest | |||
| Average |
| Dataset | ViT-B | |||||
|---|---|---|---|---|---|---|
| Decoder | En/Decoder | |||||
| V | A | L | V | A | L | |
| MRI-Prost. | ||||||
| MRI-Heart | ||||||
| MRI-Brain | ||||||
| MRI-Scler. | ||||||
| MRI-Hippo. | ||||||
| MRI-Kidney | ||||||
| MRI-Stroke. | ||||||
| MRI-Resect. | ||||||
| MRI-Breast | ||||||
| CT-Colone | ||||||
| CT-Panc. | ||||||
| CT-Vessel | ||||||
| US-Breast | ||||||
| US-Muscle | ||||||
| US-Kidney | ||||||
| Xray-Hip | ||||||
| Xray-Chest | ||||||
| Average | ||||||
| Dataset | MedSAM | |||||
|---|---|---|---|---|---|---|
| Decoder | En/Decoder | |||||
| V | A | L | V | A | L | |
| MRI-Prost. | ||||||
| MRI-Heart | ||||||
| MRI-Brain | ||||||
| MRI-Scler. | ||||||
| MRI-Hippo. | ||||||
| MRI-Kidney | ||||||
| MRI-Stroke. | ||||||
| MRI-Resect. | ||||||
| MRI-Breast | ||||||
| CT-Colone | ||||||
| CT-Panc. | ||||||
| CT-Vessel | ||||||
| US-Breast | ||||||
| US-Muscle | ||||||
| US-Kidney | ||||||
| Xray-Hip | ||||||
| Xray-Chest | ||||||
| Average | ||||||
| Dataset | SSLSAM | |||||
|---|---|---|---|---|---|---|
| Decoder | En/Decoder | |||||
| V | A | L | V | A | L | |
| MRI-Prost. | ||||||
| MRI-Heart | ||||||
| MRI-Brain | ||||||
| MRI-Scler. | ||||||
| MRI-Hippo. | ||||||
| MRI-Kidney | ||||||
| MRI-Stroke. | ||||||
| MRI-Resect. | ||||||
| MRI-Breast | ||||||
| CT-Colone | ||||||
| CT-Panc. | ||||||
| CT-Vessel | ||||||
| US-Breast | ||||||
| US-Muscle | ||||||
| US-Kidney | ||||||
| Xray-Hip | ||||||
| Xray-Chest | ||||||
| Average | ||||||
| Dataset | ViT-B | MedSAM | SSLSAM | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Decoder | En/Decoder | Decoder | En/Decoder | Decoder | En/Decoder | |||||||
| V | A | V | A | V | A | V | A | V | A | V | A | |
| MRI-Prost. | ||||||||||||
| MRI-Heart | ||||||||||||
| MRI-Brain | ||||||||||||
| MRI-Scler. | ||||||||||||
| MRI-Hippo. | ||||||||||||
| MRI-Kidney | ||||||||||||
| MRI-Stroke. | ||||||||||||
| MRI-Resect. | ||||||||||||
| MRI-Breast | ||||||||||||
| Average | ||||||||||||
| Dataset | UNet | nnUNet | SwinUNet |
|---|---|---|---|
| MRI-Prost. | |||
| MRI-Heart | |||
| MRI-Brain | |||
| MRI-Scler. | |||
| MRI-Hippo. | |||
| MRI-Kidney | |||
| MRI-Stroke. | |||
| MRI-Resect. | |||
| MRI-Breast | |||
| Average |
| Dataset | ViT-H | ViT-B | ViT-T | |||
|---|---|---|---|---|---|---|
| H | O | H | O | H | O | |
| MRI-Prost. | ||||||
| MRI-Heart | ||||||
| MRI-Brain | ||||||
| MRI-Scler. | ||||||
| MRI-Hippo. | ||||||
| MRI-Kidney | ||||||
| MRI-Stroke. | ||||||
| MRI-Resect. | ||||||
| MRI-Breast | ||||||
| Average | ||||||
| Dataset | ViT-H | |||||
|---|---|---|---|---|---|---|
| Decoder | En/Decoder | |||||
| V | A | L | V | A | L | |
| MRI-Prost. | ||||||
| MRI-Heart | ||||||
| MRI-Brain | ||||||
| MRI-Scler. | ||||||
| MRI-Hippo. | ||||||
| MRI-Kidney | ||||||
| MRI-Stroke. | ||||||
| MRI-Resect. | ||||||
| MRI-Breast | ||||||
| Average | ||||||
| Dataset | ViT-B | |||||
|---|---|---|---|---|---|---|
| Decoder | En/Decoder | |||||
| V | A | L | V | A | L | |
| MRI-Prost. | ||||||
| MRI-Heart | ||||||
| MRI-Brain | ||||||
| MRI-Scler. | ||||||
| MRI-Hippo. | ||||||
| MRI-Kidney | ||||||
| MRI-Stroke. | ||||||
| MRI-Resect. | ||||||
| MRI-Breast | ||||||
| Average | ||||||
| Dataset | ViT-T | |||||
|---|---|---|---|---|---|---|
| Decoder | En/Decoder | |||||
| V | A | L | V | A | L | |
| MRI-Prost. | ||||||
| MRI-Heart | ||||||
| MRI-Brain | ||||||
| MRI-Scler. | ||||||
| MRI-Hippo. | ||||||
| MRI-Kidney | ||||||
| MRI-Stroke. | ||||||
| MRI-Resect. | ||||||
| MRI-Breast | ||||||
| Average | ||||||
| Dataset | ViT-H | ViT-B | ViT-T | MedSAM | SupSAM | ||||
|---|---|---|---|---|---|---|---|---|---|
| H | O | H | O | H | O | H | O | - | |
| MRI-Prost. | |||||||||
| MRI-Heart | |||||||||
| MRI-Brain | |||||||||
| MRI-Scler. | |||||||||
| MRI-Hippo. | |||||||||
| MRI-Kidney | |||||||||
| MRI-Stroke. | |||||||||
| MRI-Resect. | |||||||||
| MRI-Breast | |||||||||
| Average | |||||||||
| Dataset | ViT-H | |||||
|---|---|---|---|---|---|---|
| Decoder | En/Decoder | |||||
| V | A | L | V | A | L | |
| MRI-Prost. | ||||||
| MRI-Heart | ||||||
| MRI-Brain | ||||||
| MRI-Scler. | ||||||
| MRI-Hippo. | ||||||
| MRI-Kidney | ||||||
| MRI-Stroke. | ||||||
| MRI-Resect. | ||||||
| MRI-Breast | ||||||
| Average | ||||||
| Dataset | ViT-B | |||||
|---|---|---|---|---|---|---|
| Decoder | En/Decoder | |||||
| V | A | L | V | A | L | |
| MRI-Prost. | ||||||
| MRI-Heart | ||||||
| MRI-Brain | ||||||
| MRI-Scler. | ||||||
| MRI-Hippo. | ||||||
| MRI-Kidney | ||||||
| MRI-Stroke. | ||||||
| MRI-Resect. | ||||||
| MRI-Breast | ||||||
| Average | ||||||
| Dataset | ViT-T | |||||
|---|---|---|---|---|---|---|
| Decoder | En/Decoder | |||||
| V | A | L | V | A | L | |
| MRI-Prost. | ||||||
| MRI-Heart | ||||||
| MRI-Brain | ||||||
| MRI-Scler. | ||||||
| MRI-Hippo. | ||||||
| MRI-Kidney | ||||||
| MRI-Stroke. | ||||||
| MRI-Resect. | ||||||
| MRI-Breast | ||||||
| Average | ||||||