
1 Introduction
Image segmentation plays a fundamental role in the analysis of biological images. It enables the extraction of quantitative information on diverse objects ranging from molecules, droplets, membranes, nuclei, cells, vessels or other structures. In modern biological research, accurate segmentation is often pivotal to better understand the mechanisms of life. The increasing availability of high-throughput imaging technologies has led to a surge in the quantity and complexity of image data, raising significant challenges and opportunities. Manual annotation of the resulting images is labor-intensive, time-consuming, and often impractical for large-scale datasets. Automated segmentation is therefore widely accepted as a critical step in biological research.
A simplified history of cell segmentation
Image segmentation has long been dominated by handcrafted algorithms. The processing pipelines typically combine popular tools such as linear filtering, thresholding Otsu (1979), morphological operations Serra and Soille (2012); Legland et al. (2016), active contour models (Snake) Kass et al. (1988) or watershed Vincent and Soille (1991). A significant issue with handcrafted approaches is that they are usually image-specific and rely on the manual tuning of a few complicated hyper-parameters. Although excellent performance can be achieved, it is often the work of a handful of talented people and these techniques are not broadly applicable.
The introduction of machine learning and especially random forests made image segmentation accessible to a much larger range of researchers. These techniques automatically combine and tune elementary image processing bricks. They are driven by a few easily interpretable user annotations. Embedded in well conceived software such as Ilastik Berg et al. (2019) or Labkit Arzt et al. (2022), these techniques heavily contributed to democratize image segmentation and classification.
Deep learning and convolutional neural networks played an important role in improving the segmentation performance around 2015. For instance, the popular U-Net architecture Ronneberger et al. (2015) increased the accuracy on some cell segmentation challenges by more than 10%, which can be considered as a small revolution. This type of neural network architecture seems to be a good prior for segmenting “natural” images, as suggested by the so-called Deep Image Prior principle Lempitsky et al. (2018). However, it can sometimes demonstrate limited effectiveness when it comes to separating nearby or touching objects. Many applications in biology involve densely packed objects (e.g. cells, nuclei) and a pixel-classification U-Net is often insufficient to perform a satisfactory analysis. To address this issue, new architectures coming from computer vision such as Mask R-CNN He et al. (2017) have been developed and continued improving the performance.
Roughly at the same time, a few approaches (Deep watershed transform Bai and Urtasun (2017), Deep Regression of the Distance Map Naylor et al. (2018); Kumar et al. (2019), StarDist Schmidt et al. (2018), Hover-Net Graham et al. (2019), Cellpose Stringer et al. (2021), Omnipose Cutler et al. (2022)) have been developed and generated results with an unprecedented quality. Despite certain differences, they all share a common underlying principle. The idea is to make a regression with respect to some distance function. Given a set of annotated objects, a distance function to the objects centers or boundaries is computed. A convolutional neural network is then trained to predict the distance function rather than a binary map of the objects. The gradient of this distance function points in opposite directions on each side of the boundary, which makes it possible to determine them with much greater precision. This principle created a new gap in the segmentation accuracy, especially for objects with touching boundaries.
A current trend consists in involving the user in the training procedure. This “human in the loop” principle was incorporated in CellPose 2.0 Pachitariu and Stringer (2022). Users fully annotate patches of the segmented image, to adapt the neural network weights to the image at hand.
It would be hazardous to call these approaches the current “state-of-the-art”, since this field is expanding extremely quickly. However – as of 2025 – we can safely claim that algorithms based on the distance map are at the basis of some of the most popular and efficient cell segmentation methods.
Contributions
This work stems from a practical observation: methods which rely on a regression to the distance function currently require exhaustive annotations. As the distance function is a global geometrical property, it is impossible to compute it using just a few sketches. Hence, it is a priori unclear how partial annotations can be used in this framework, see Figure 1. Cellpose 2 gets around this problem by allowing the user to annotate patches of interest in their entirety. Similarly, Sugawara (2023) recently proposed a simple extension of Stardist and Cellpose by training the networks on a subset of completely annotated objects. This is a time-consuming process that does not allow the expert to focus on local spots (e.g. a part of boundary) where the network clearly missed the segmentation.


In this paper, we introduce a novel idea that allows us to use the distance function even with partially annotated objects. After drawing just a few regions and boundaries, the user can train a task-aware neural network. This approach capitalizes on the generalization capacity of neural networks, reducing the overall annotation effort without sacrificing accuracy. We explore the performance of the proposed architecture in 3 different settings:
- •
Few-shot learning: starting from random weights, we show that just a few partial annotations are already enough to quickly realize complex cell segmentation analyses. This is interesting when faced with a problem for which no close pre-trained model exists.
- •
Transfer learning: starting from Omnipose’s optimized weights, we show that just a few clicks at locations where the segmentation is inaccurate lead to improved weights and fast adaptation to out-of-distribution images. This is the traditional field of transfer learning, domain adaptation, e.g.. Our contribution here is to show that this can be done with only a few scattered annotations.
- •
Large databases: finally, we show that large, but partially annotated sets can also be used to train high performance neural networks. This is important since it can significantly accelerate the design of segmentation databases.
This evaluation on both small and large-scale dataset, overall showcases the advantages of our approach in terms of time and resource savings. We developed a Napari plugin Chiu et al. (2022) named Sketchpose, to assess its potential, ensure reproducibility of the results and provide an additional tool to the community. It relies on a modified version of the Omnipose Cutler et al. (2022) algorithm. The plugin is currently being downloaded regularly, with 638 downloads to date.
2 Methodology
2.1 Preliminary definitions and notations
In all the paper refers to the image domain, which can be understood as a discrete set of coordinates, or as a continuous domain depending on the context. In the discrete setting, we let denote the number of pixels of .
Definition 1
For an arbitrary set , we let denote its boundary. We use the 4-connectivity (top, bottom, left, right) in the discrete setting.
Definition 2 (Point to set distance)
The distance from a point to a set is defined by
| (1) |
2.2 Omnipose
Our work is based on the Omnipose cell segmentation architecture Cutler et al. (2022). In this section, we justify this choice, explain its founding principles and then demonstrate how they can be adapted to deal with partial annotations.
2.2.1 Why Omnipose
Cellpose Stringer et al. (2021) has now become a standard in cell segmentation. Its excellent perfomance, processing speed, and ergonomic graphical interface make it a handy tool for every day cell biology image analysis. However, it occasionally fails in scenarios involving complex and elongated objects. In such cases, it tends to produce over-segmentation, where neighboring objects are split in smaller fragments.
The Omnipose algorithm Cutler et al. (2022) was conceived in order to address this limitation. The main difference between Omnipose and Cellpose is the fact that the distance map is defined as the distance to the cell boundaries in Omnipose, while it is defined as a distance to a cell “centroid” in Cellpose. A weakness of the latter is that there is no canonical choice to define this center, hence Omnipose’s choice seems more principled. This explains our decision to choose and base our work on its architecture.
2.2.2 The main principles

Figure 2 summarizes the main ideas behind the Omnipose architecture and its training. Omnipose is based on a regular convolutional neural network (CNN), with a U-Net like architecture Ronneberger et al. (2015). Given an input 2D image with pixels, the CNN can be seen as a mapping of the form
| (2) |
It depends on weights that should be optimized during a training stage. It returns different outputs (illustrated on the top of Figure 2):
- •
boundary probability: at every pixel, the value of this image can be interpreted as a probability of being a boundary between the objects to segment.
- •
distance map: at a given pixel, the value of this map is equal to:
- –
The distance of the pixel to the closest object boundary, if the pixel is inside an object.
- –
(or a fixed negative value) elsewhere.
- –
- •
flow field: can be interpreted as the gradient of the distance map. It is an essential feature of the Cellpose and Omnipose architectures. Ultimately, the flow is used through a procedure called Euler integration to generate a segmentation mask. This is illustrated on the top right of Figure 2.
2.2.3 The original loss definition
The original training stage involves a collection of images together with their exhaustive segmentation masks. For every image in the dataset, an algorithm creates the gold standard boundary probability , distance map and flow field . This is illustrated on the bottom of Figure 2.
The weights of the neural network are then optimized so as to minimize a loss function that compares the output of the CNN with the gold standard:
| (3) |
where , , .
In the original Omnipose implementation available on GitHub, the different losses were defined as follows:
- •
Boundary loss :
This term compares the predictions to using the following loss:
(4) where combines a sigmoid and a binary cross entropy loss.
- •
Distance loss :
This loss calculates a weighted mean squared error between the predicted distance fields and the ground truth distance fields. It is defined as
where is a weight image with higher values around the gold standard boundaries.
- •
Flow loss :
This loss is defined as a weighted sum of three losses . The first one is a mean squared error loss:
(5) The second one compares the norms of the vector fields:
(6) The third one aims to minimize the distance between trajectories generated through the ground truth and predicted flows. Trajectories starting from an initial point can be generated by simple explicit Euler discretization:
where is a step-size. Letting denote an integration time, the “Euler” loss then becomes:
(7) It measures how two trajectories generated by Euler integration using the ground truth and predicted vector fields deviate. This loss is implemented in the torchVF library by Peters (2022). For more information, we refer the reader to the related report.
An inspection of the code reveals that the different weights have been set empirically as: , , , , .
Remark 3
The different losses have probably been combined by trial and error to produce the best possible results. However, there are clear redundancies in the definitions of the losses, for instance , and are all measuring the distance between flows using different metrics. In our implementation, we tried to simplify the losses as much as possible, while still maintaining a good performance.
2.3 Adapting to partial annotations
All the principles described above heavily depend on an exhaustive segmentation of the cells. Indeed, the distance functions and gradient flows – which are instrumental to define the loss functions – are global properties which do change heavily if the objects boundaries are incomplete. In this section, we describe the main methodological contribution of this paper, which will allow us to handle partial boundaries.
2.3.1 The gold standard

| Notation | Description |
|---|---|
| Image domain | |
| True background | |
| True foreground | |
| Background strokes | |
| Foreground strokes | |
| True boundaries | |
| User-defined boundaries | |
| Valid distance set |
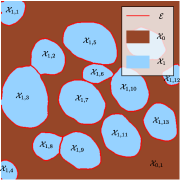
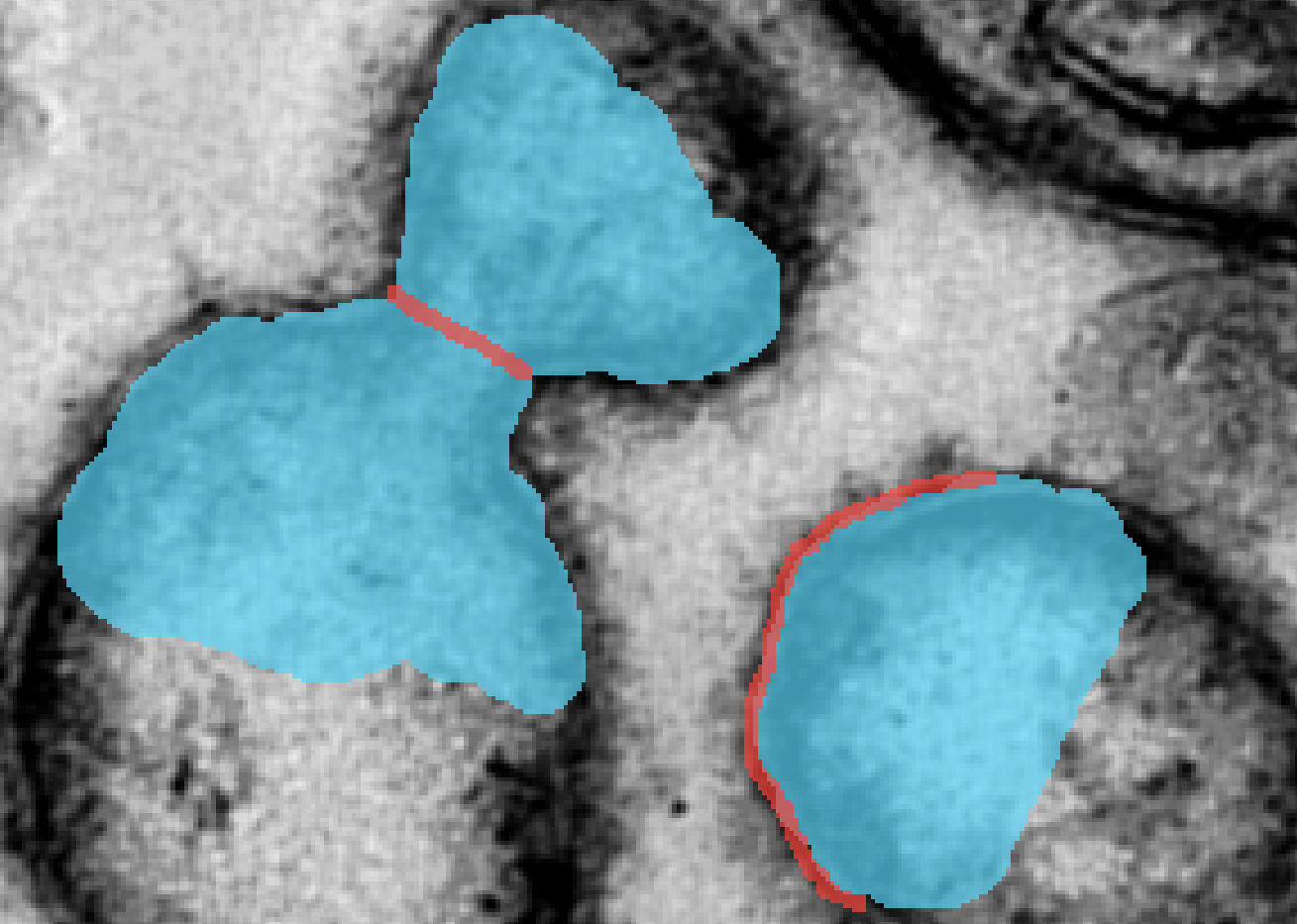
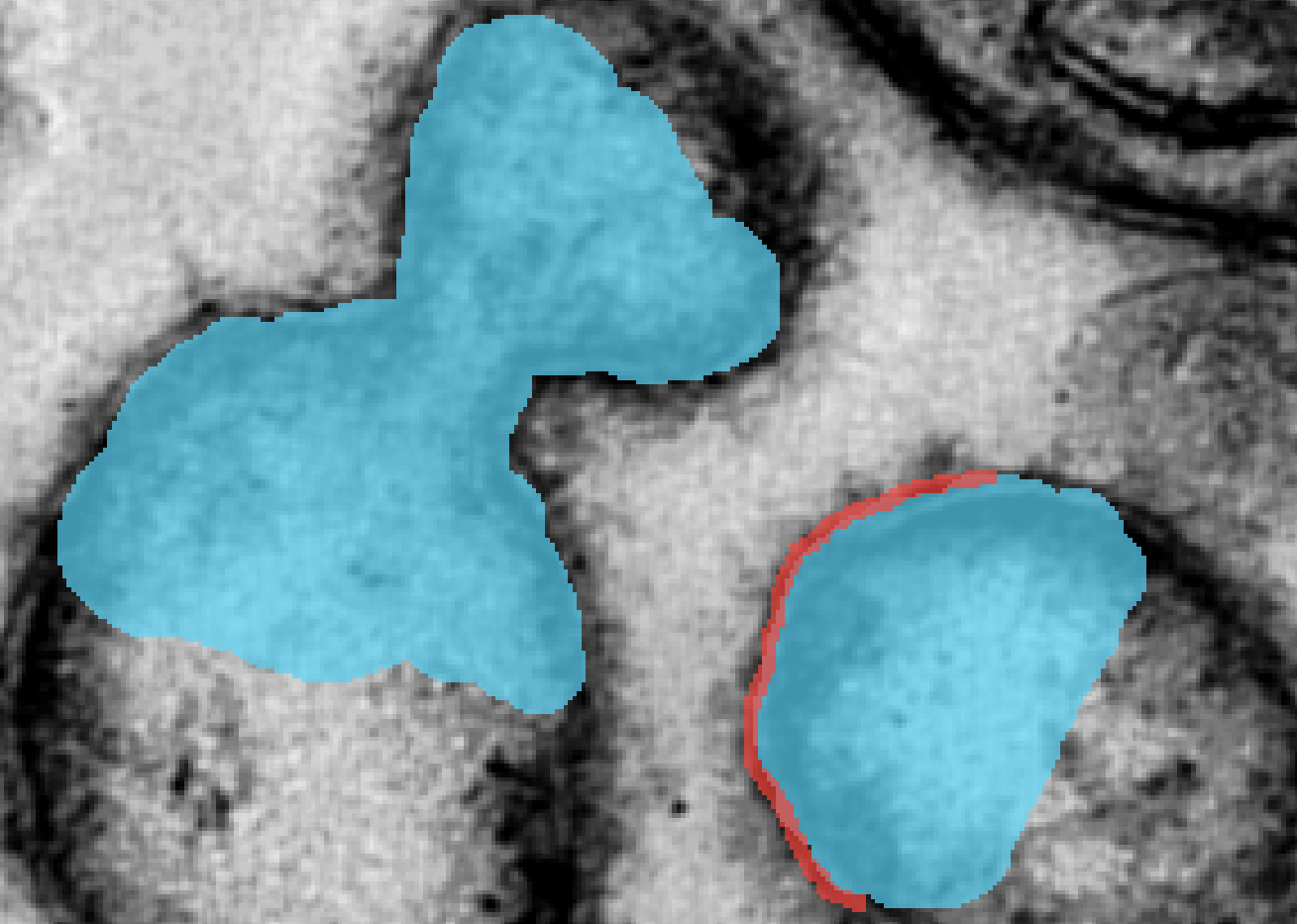
The notations are summarized in Table 1. We assume that the domain is partitioned with the background set and the foreground set . A difficulty in instance segmentation is that multiple objects may exist within the connected components of a region . To differentiate them, we let denote a partition of the set as different objects within a similar class. For instance in Figure 3(a), the foreground set is split in 13 components. A connected component of can be split as . The background set is split in a single component .
We let
| (8) |
denote the set of all edges (or object boundaries) within the image. It is depicted in red in Figure 3(a).
2.3.2 The annotation set
The input of our neural network is a set of “sketches” or strokes drawn by the user. We let and denote the strokes describing the background and foreground respectively. They are depicted in brown and blue respectively in Figure 3(b). The intersection of the brown and blue strokes define natural boundaries. We can indeed construct the touching boundaries between different strokes as
where is the closure of in the continuous setting and the interface between neighboring pixels in the discrete setting.
In addition, the user can delineate other boundaries, denoted , to separate touching objects within a class. We can concatenate all the boundaries to obtain a complete boundary set defined as
| (9) |
For the algorithm to work properly, we require the following set of assumptions.
Assumption 1 (Assumptions on the strokes)
- •
The strokes correctly separate the background and foreground: and .
- •
The strokes do not overlap: . This is actually forced by our Napari interface.
- •
The boundaries are a subset of the exact boundaries , that is:
(10) - •
If the stroke contains multiple objects, then the boundaries between the objects need to be completely drawn with (see Figure 3(d)). Letting denote the complete stroke set drawn by the user, this condition reads:
(11)
2.3.3 The main observation
The main result we will use to define and certify our algorithm is summarized in the following theorem.
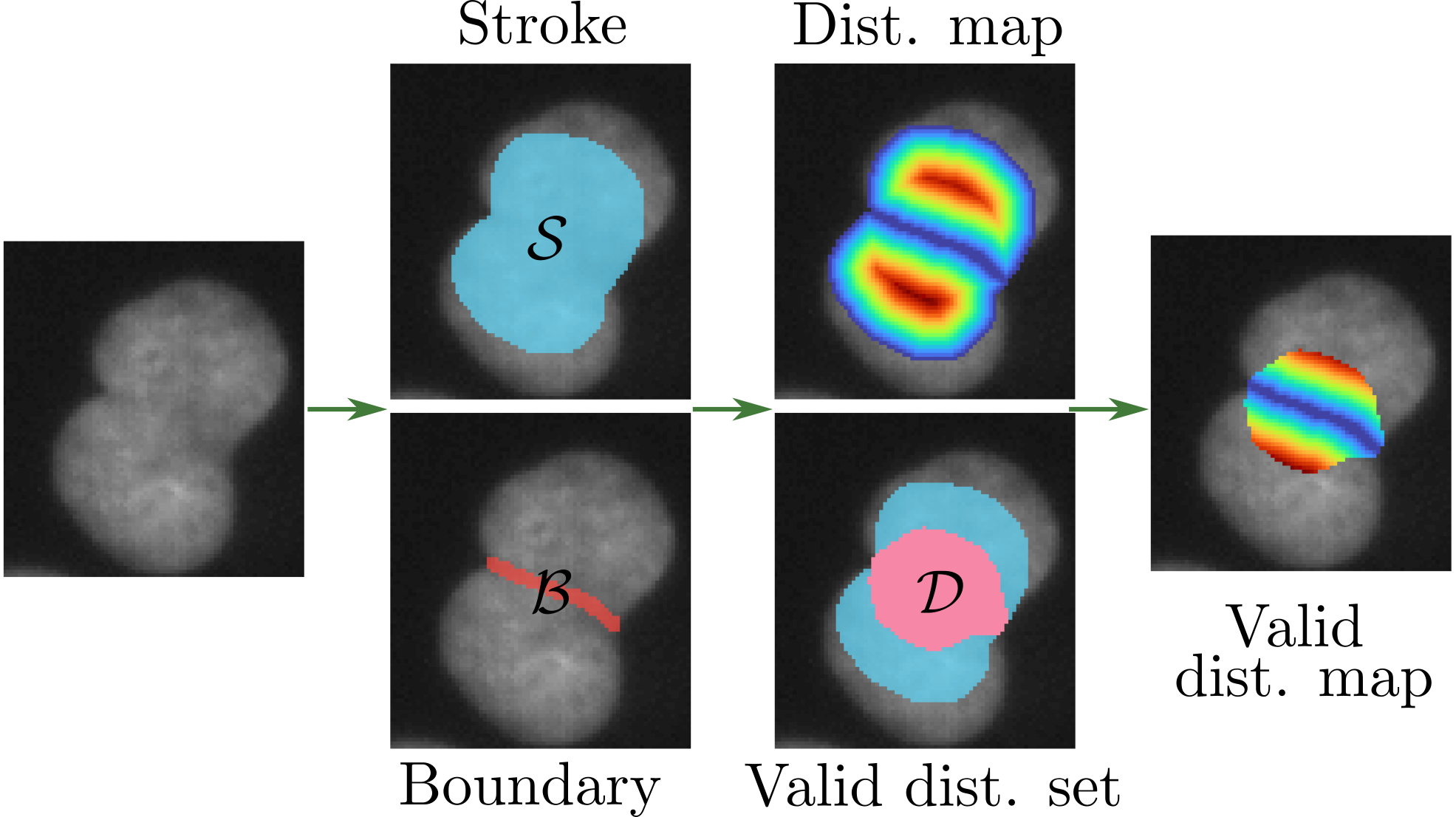
Theorem 4 (The valid distance set)
Let denote the complete set of annotation boundaries and define the valid distance set as
| (12) |
The following relationships hold:
The proof of this theorem is given in Appendix A. This theorem should be understood as follows. The first identity informs us that we can compute the exact distance map to the set of exact boundaries on the valid set . This set can be computed using only the partial annotations of the boundaries and the different semantic regions . The second inequality tells us that we have an information everywhere on the strokes and . Moreover, in the case of total annotations, we get and the proposed idea will lead to a training equivalent to the one in Omnipose and we can see the proposed setting as a generalization. Figure 4 schematically summarizes Theorem 4.
2.3.4 Adapting the training
A simpler architecture
The prediction of the boundaries is not necessary, since only the distance map and the flow field are needed to compute the final masks. Hence, we keep the same U-Net architecture, but remove the channel associated to the boundaries:
| (13) |
Different summation sets
Equipped with the valid distance set , we are ready to adapt the losses to cope with partial annotation. In Omnipose, the losses , , and are defined by summation over the set (see paragraph 2.2.3). With partial annotation, the gold standard is not properly defined on this set and we therefore need to change the summation sets.
Dealing with inequalities
Until now, we just used the first identity in Theorem 4, but the second inequality brings some additional information. We propose to integrate it in the training through the additional asymmetric loss:
| (14) |
Putting it all together
We can now define the total sketchpose loss as:
| (15) |
where are obtained by the simplified neural network .
2.4 The Sketchpose plugin
A significant part of this work lies in the development of a user-friendly graphical interface to train and use the neural network. It is integrated in Napari Chiu et al. (2022), which is well suited to embedding the Python/PyTorch codes at the core of our approach.
Sketchpose can be easily installed through either the pip package manager or Napari’s Chiu et al. (2022) built-in interface. A detailed documentation can be accessed by clicking on this hyperlink. It offers step-by-step instructions illustrated by short videos, to assist users in effectively testing all the capabilities of the plugin.
The user directly draws a few strokes for the background, foreground and boundaries. The brush size can be adjusted similarly to usual paint software. An entire stroke boundary can be added to the boundary set by a double right-click. The training and drawing can be achieved in parallel to target the places where the segmentation is inaccurate.
The networks can be initialized by random weights or existing pre-trained weights. The multi-threaded plugin’s architecture makes it possible to annotate, train and observe the current segmentation results simultaneously. The user can annotate regions where the segmentation is inaccurate in priority, hence reducing the annotation time. The predictions can be restricted to a bounding box at each epoch of the training process, to reduce the processing time, which is particularly helpful for large scale images. Finally, users can work with a single image or a set of images for the inference and training steps.
3 Experiments
In this paragraph, we conduct several experiments to explore three distinct use cases of the method.
- •
Learning from a limited set of annotations on a single image with randomly initialized neural network weights.
- •
Learning from a limited set of annotations on a single image, starting from a pre-trained neural network.
- •
Learning with randomly initialized weights using a large dataset with sparse annotations. We study the impact of the percentage of labeled pixels (10%, 25%, 50% and 100%) on the segmentation quality, when training on thousands of cells.
After describing the metrics used for validation, we will turn to the practical results. For all the experiments, we used a single Nvidia RTX5000 GPU with 16 Gb.
3.1 Evaluation metrics
To quantify the predictions quality, we enumerate the true positives (TP), the true negatives (TN) and the false positives (FP). A true positive is an object in the gold standard that can be matched to an object in the prediction with an Intersection over Union (IoU) criterion higher than a threshold . We let denote the total number of true positives. The total number of estimated objects without matches is denoted (for false positives). The total number of gold standard objects without valid matches is denoted (for false negatives). Utilizing these values, we compute the object detection accuracy metric () Caicedo et al. (2019) for each image using the formula:
The reported object dectection accuracy is then computed as the average over all images in the test set.
Additionally, we computed the average DICE and the Aggregated Jaccard Index defined as follows:
where and are a dataset and its groundtruth.
3.2 Training from scratch on a single image
In this section, we will showcase several results achieved while training from scratch on a small set of images. The tests are made on a variety of biological structures (dendritic cells, osteoclasts, bacteria, insect eggs, adipose tissue, artistic image of cells).
3.2.1 Training details
For this experiment, the model have been trained for 100 epochs ( 2 minutes) with a batch size of 16 and image flips for data augmentation.
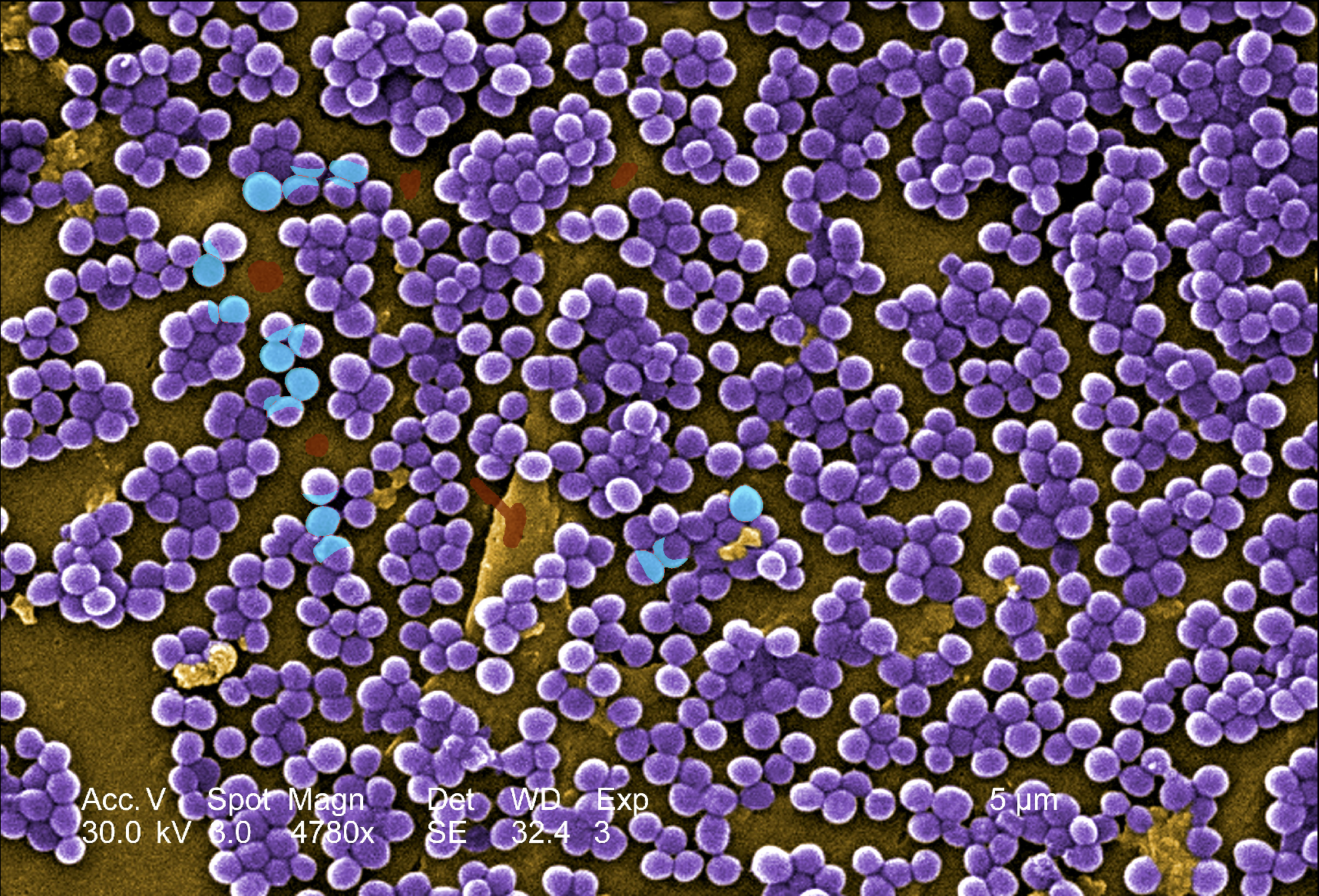
3.2.2 Staphylococcus aureus
In the example of Figure 5, we use a microscopy image of methicillin-resistant Staphylococcus aureus (MRSA) infections, from European Commission, Horizon Magazine (2020), “Can we reverse antibiotic resistance?”. It is reused under the European Commission’s reuse policy.
3.2.3 Eggs on a tree leaf
In this section, we picked an image from the Omnipose dataset, which likely represents eggs of an insect on a tree leaf. At first sight, the segmentation task is uneasy, since the objects are tightly connected, with identical textures and blurry boundaries. We first annotated a subset of 5 eggs in Figure 6(b) with a minimal amount of background. The segmentation result after training is already surprisingly good in Figure 6(d), but some objects are not detected, and others are merged. We annotated 2 extra eggs in Figure 6(c). With this extra information, retraining the network now produces a near perfect segmentation mask, with a single error (2 pink eggs on the left). This experiment illustrates a unique feature of Sketchpose: it is possible to interactively annotate while training. This offers a possibility to label a minimum amount of regions to reach the desired output. This principle sometimes called “active learning” or “human-in-the-loop” Budd et al. (2021) is significantly enhanced by using partial annotations and the user-friendly Napari interface.





3.3 Transfer learning on a single image
In this section, we explore the feasibility of improving pre-trained weights using transfer learning.
3.3.1 Training details
As for the previous experiment, the model have been trained for 100 epochs ( 2 minutes) with a batch size of 16 and image flips for data augmentation.
3.3.2 Bacteria segmentation
Bacteria are often used as biological models (e.g. in DNA studies). A precise segmentation can be difficult to achieve, because they have elongated shapes and can be clustered.
The Omnipose Cutler et al. (2022) model was initially conceived to address the shortcomings of Cellpose for this task.
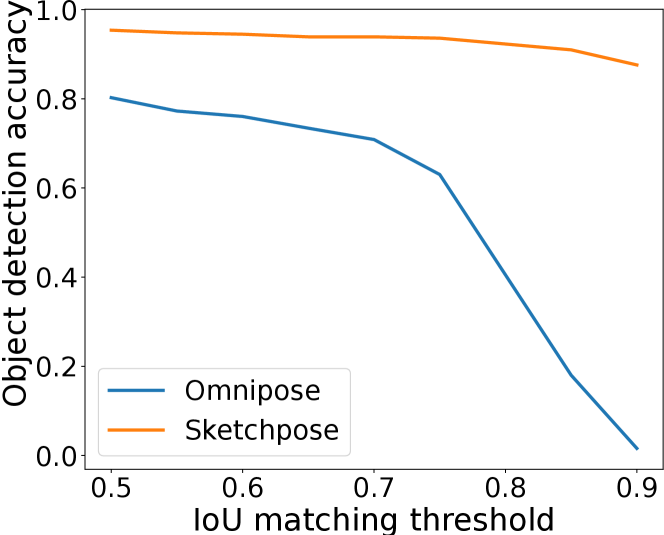
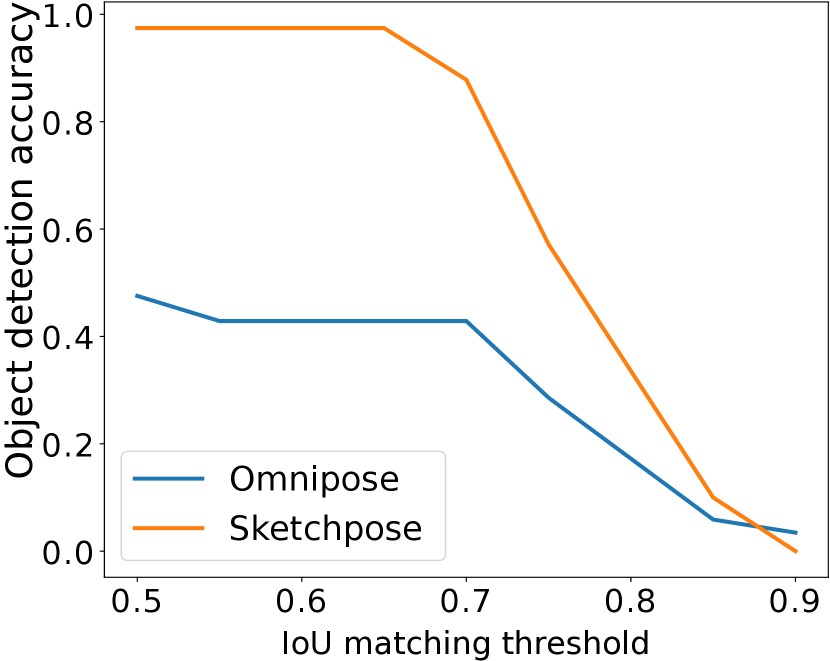
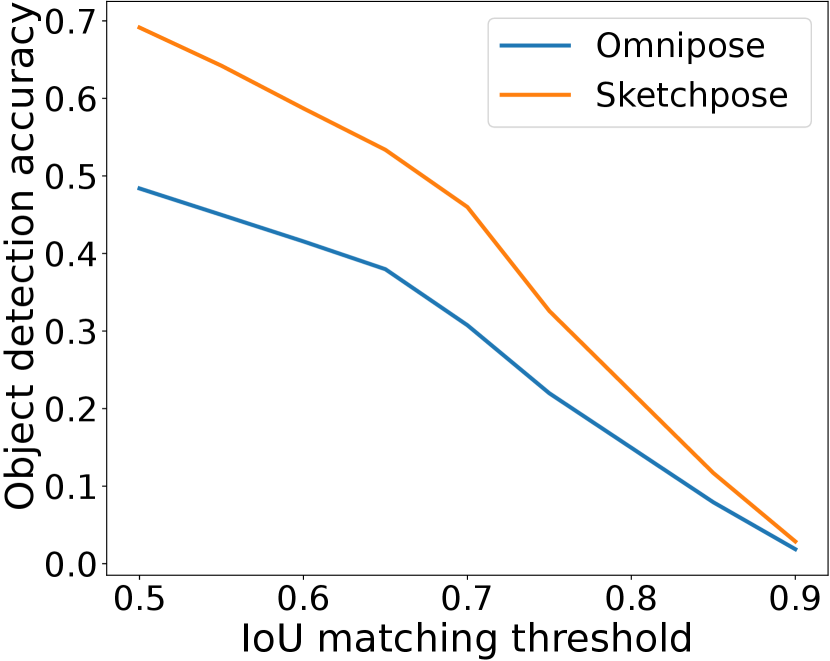
Figure 7 shows how transfer learning with sparse annotations can improve the Omnipose results by separating touching bacterias. Figure 7(d) shows a quantitative comparison of both methods. As can be seen, Sketchpose’s adapted weights provide much higher performance. A visual inspection indicates that all objects have been correctly separated, apart from the cluster touching the boundary on the bottom left.
3.3.3 Adipocytes segmentation
The image in Figure 7(e) shows a crop of a very large image of a skin explant provided by DIVA Expertise. One can see a part of the dermis (in pink) and above it, adipose tissue (large white circular cells). Adipose tissue is the third skin layer after the epidermis and dermis, also known as the hypodermis. Hypodermal cells (adipocytes) secrete specific molecules (e.g. adiponectin, leptin) which have a direct impact on the biology of fibroblasts present in the dermis, and also on keratinocytes present in the epidermis. They are the subject of numerous studies (see Bourdens et al. (2019) and Sadick et al. (2015) for instance). For most of the studies where skin explants are imaged, we first need to count the adipocytes number in the image, and remove any potential outliers detected in the dermis and epidermis.
While Omnipose cyto2 results in some undersegmentation for this task, the adapted weights provided by Sketchpose yields significantly enhanced results. Annotating 6 cells and a training for 100 epochs (less than 1 minute) were sufficient to significantly improve the quality of the segmentation and to remove the outliers from the dermis (see Figure 7(c)). Figure 7 shows a quantitative comparison between Omnipose and Sketchpose on this example.
3.3.4 Osteoclasts segmentation
Osteoclasts are responsible for bone resorption, and are widely studied (see Labour et al. (2016) for instance) as being responsible for certain pathologies such as osteoporosis when dysfunctional. Their differentiation goes through several stages, culminating in the activated osteoclast. The latter is generally large and contains numerous nuclei. Atlantic Bone Screen (ABS) company is investigating the effect of different drugs in inducing either proliferation or cell death in these activated osteoclasts, in order to regulate their population. To do so, they extract osteoclasts from biopsies, culture them, apply the drugs and image them under a bright-field microscope.
The studied image is a crop of an image containing around 20,000 cells. We can see touching cells presenting a great variety in size, shape color. The image is complex to segment and poses a real challenge. What is more, ABS does not want to count pre-osteoclasts (small black nuclei), but only the mature cells (according to specific nuclei criteria). Each study comprises around sixty images, hence manual counting task performed at ABS is costly and laborious.
In Figure 7, we present a qualitative depiction that underscores the enhancement in segmentation accuracy attained through transfer learning with just a few labels. Labeling required approximately 2 minutes, while the training process took about 5 minutes. A quantitative comparison is available in Figure 7(l).
3.4 Training from scratch on large datasets
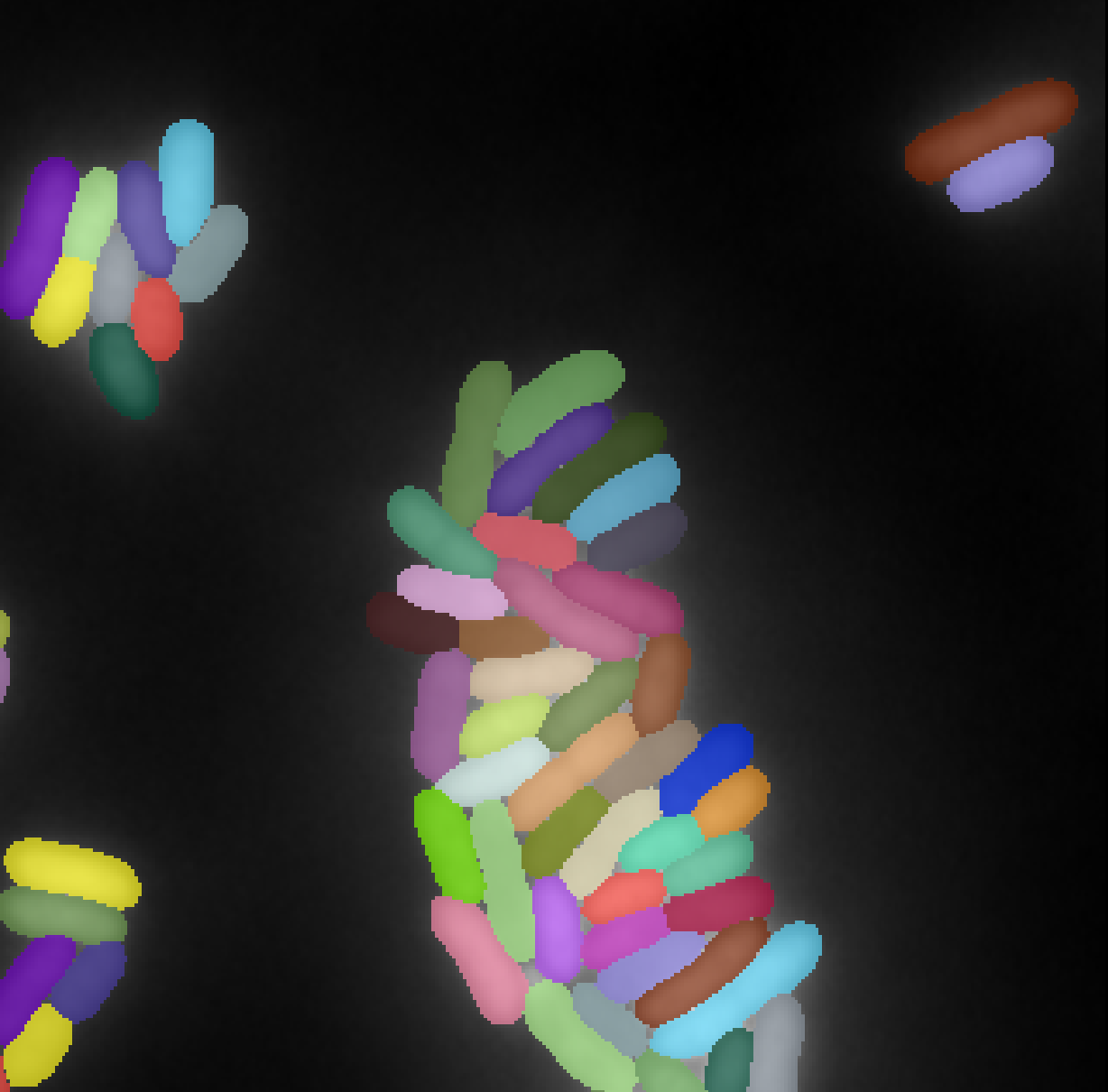
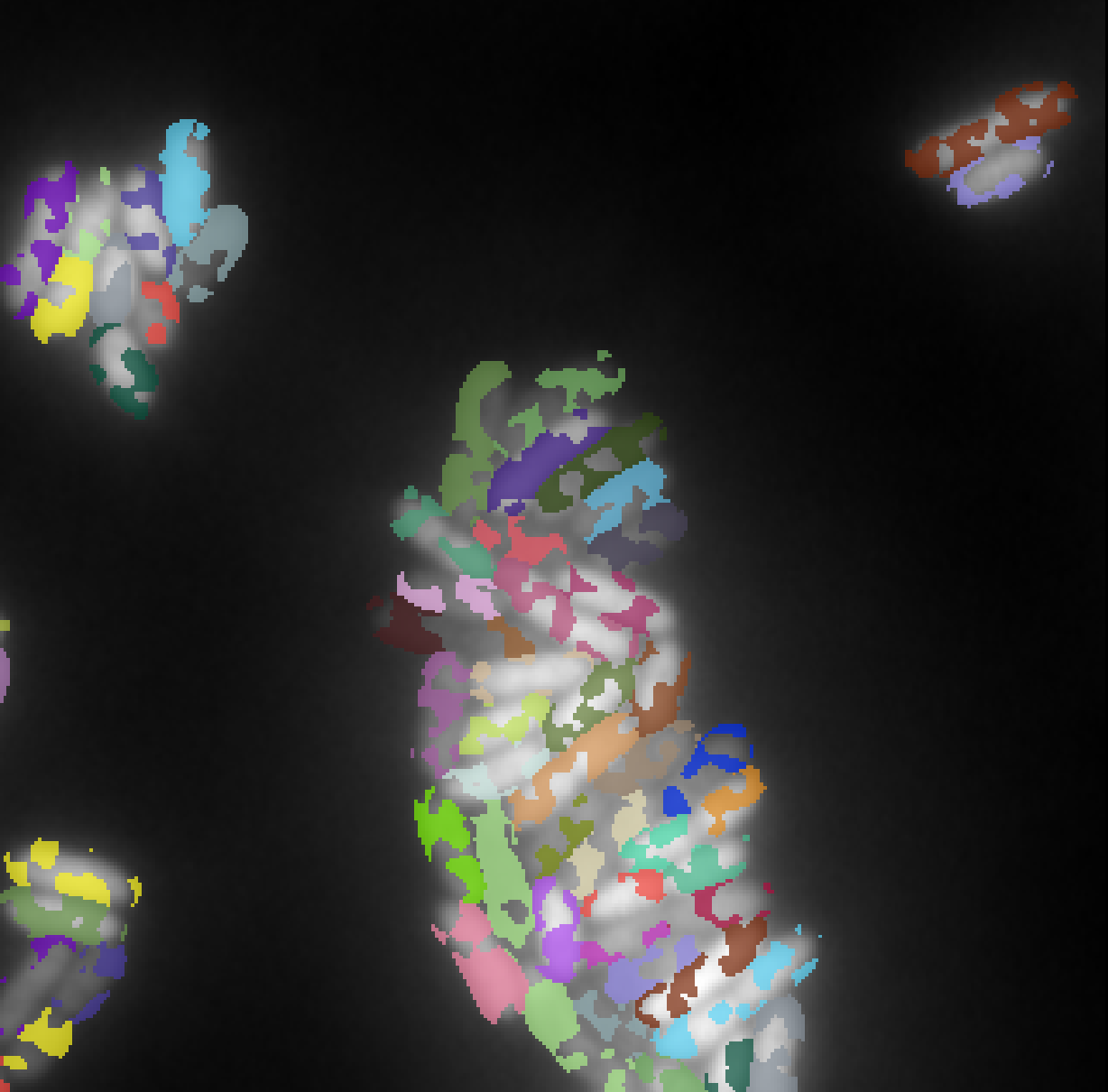
The aim of this experiment is to highlight the possibility to train our model on large datasets with sparse annotations. We use two different datasets as illustrated in Figure 8.





Microbeseg dataset
PanNuke dataset
The PanNuke dataset Gamper et al. (2019) contains 7,904 image tiles of histopathology slides stained with H&E across 19 tissue types, each with nuclear instance segmentations and five-class nuclear type annotations. It is publicly available from Kaggle and is widely used for benchmarking nucleus segmentation and classification algorithms.
3.4.1 Selecting annotation subsets
In this section, we investigate the model robustness across various annotation levels each characterized by a different percentage of annotated pixels: 10%, 25%, 50%, and 100%. We generate randomly binary masks by thresholding white Gaussian noise with a Gaussian filter of variance . The resulting Gaussian process is then thresholded to keep only a given proportion of pixels.
While the model is stochastic in nature, the generated data is created once and for all, enabling its deterministic reuse across multiple training sessions. Figure 9 shows an image accompanied by four corresponding label masks illustrating decreasing levels of annotation sparsity.

3.4.2 Training details
For each dataset, we trained the Sketchpose model for 1000 epochs. This takes about 5 hours for the Microbeseg dataset and 30 hours for the PanNuke dataset using our Nvidia RTX5000. Each model was trained with the four percentages of annotated pixels we described above. There was no data augmentation, except random cropping of the images to 224x224 pixels. This is the size which was used in the original Omnipose model.
3.4.3 Results
We evaluated and compared the performance using two alternative models. The first one is the Cellpose 3.0 model Stringer and Pachitariu (2025), which regresses a distance to the objects centroids. The second one is the LKCell model Cui et al. (2024), which is a better performing variant of CellVit Hörst et al. (2024), itself a variant of HoverNet Graham et al. (2019). These models are among the most popular and best performing for histopathology images such as the PanNuke dataset. While they perform classification and segmentation, we will just compare their ability to segment objects, as we are not interested in the classification task here. We trained both LKCell and Cellpose 3.0 from scratch on each of the two datasets with complete annotations for 1000 epochs.
We compare the performance using other standard quality metrics used in instance segmentation. In all the metrics below, an IoU threshold of 50% is used.
- •
Precision: measures how many of the predicted positives are actually correct (i.e., the fraction of predicted segments that are true).
- •
Recall: how many of the actual positives were correctly predicted (i.e., how complete the prediction is).
- •
F1-Score: harmonic mean of precision and recall, balancing both.
- •
Detection Quality (DQ): evaluates object-level detection performance, penalizing missed or extra objects. It evaluates the ability to detect object instances correctly, regardless of segmentation quality.
- •
Segmentation Quality (SQ): measures how well matched objects are segmented, assuming correct pairing, reflecting the quality of the predicted segment.
The main results are reported in Table 2, and several key observations emerge.
Best-performing methods
On the MicrobeSeg dataset, Cellpose and Sketchpose (100% annotations) deliver the best performance, while LKCell lags behind with a 15% lower F1-score. Conversely, on PanNuke, LKCell outperforms both competitors with a 4–6% F1-score gain, confirming its suitability for this dataset.
Impact of annotation density
For MicrobeSeg, reducing annotation density leads to a significant performance drop for Sketchpose: around 10% at 50–25% annotations, and up to 20% with only 10%. Depending on the application, such degradation may or may not be acceptable.
The situation is more favorable for PanNuke. Sketchpose maintains stable performance, with only a 4% drop when reducing annotations from 100% to 10%. Given that sparse annotations likely reduce annotation time by a factor of ten, this is a promising result—especially since random sampling was used. In practice, targeted annotations by an expert would likely yield even better outcomes.
This contrast may stem from dataset characteristics: PanNuke contains simpler, roughly convex objects, while MicrobeSeg features elongated or irregular shapes, making annotation density more critical.
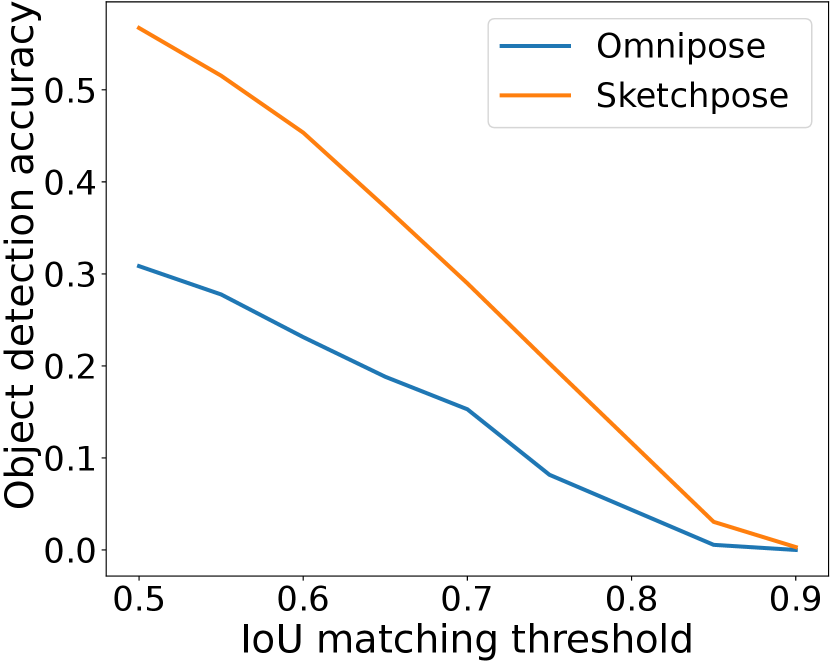
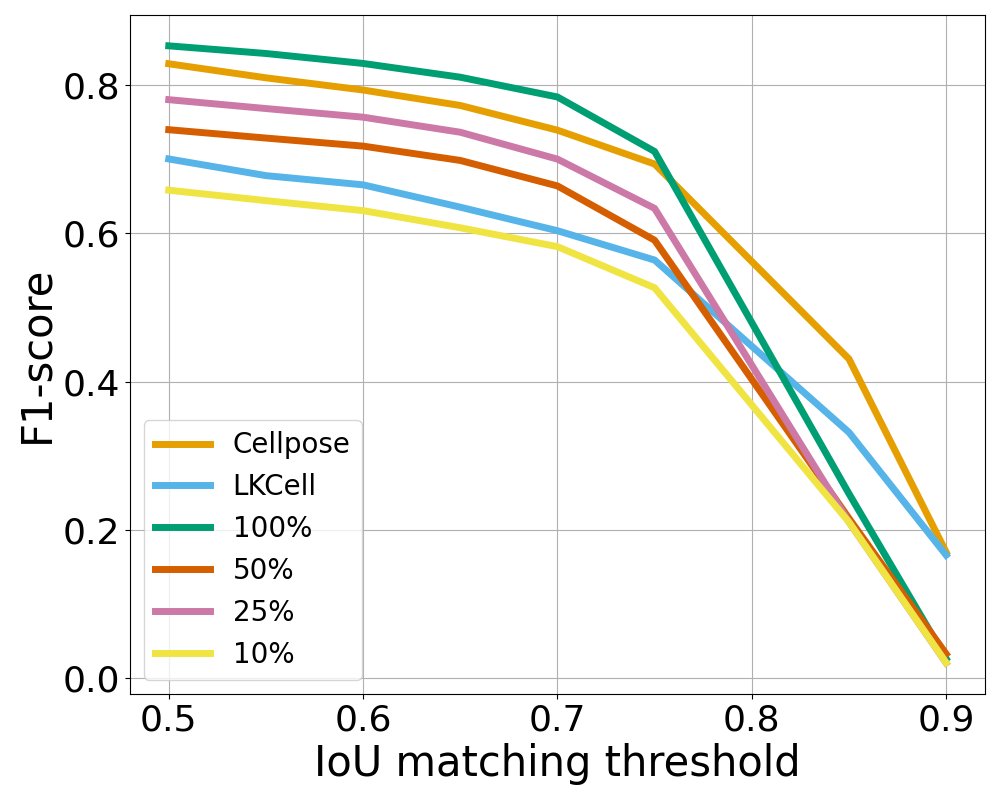
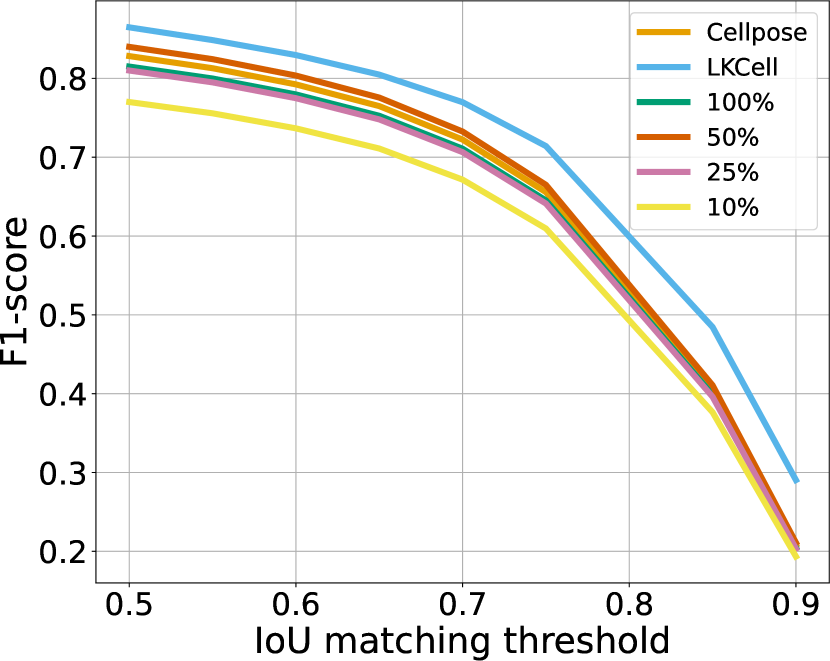
IoU matching thresholds
To provide a refined view of the performance, we also plot the F1-score as a function of the IoU matching threshold in Figure 10. There, we see that the ranking between the methods is stable up to a mathcing threshold of 70%, which is usually considered a high precision segmentation in biological imaging. A surprising phenomenon is that Sketchpose trained with 25% of annotations performs better than the 50% model on the MicrobeSeg dataset. Similarly, the 50% model performs better than the 100% model on the PanNuke dataset. This might indicate that carefully selected annotations can lead to better results than complete annotation, or helps reducing the influence of errors in the gold-standard database.
Sketchpose is the first distance-based method allowing to take advantage of this observation.
| MicrobeSeg dataset | PanNuke dataset | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LKCell | Cellpose | 100% | 50% | 25% | 10% | LKCell | Cellpose | 100% | 50% | 25% | 10% | |
| Precision | 0.73 | 0.88 | 0.77 | 0.63 | 0.68 | 0.55 | 0.82 | 0.88 | 0.86 | 0.84 | 0.78 | 0.75 |
| Recall | 0.65 | 0.75 | 0.89 | 0.86 | 0.83 | 0.78 | 0.84 | 0.71 | 0.71 | 0.75 | 0.77 | 0.73 |
| F1-Score | 0.66 | 0.79 | 0.81 | 0.69 | 0.72 | 0.60 | 0.83 | 0.78 | 0.77 | 0.79 | 0.77 | 0.73 |
| DICE | 0.82 | 0.86 | 0.85 | 0.85 | 0.83 | 0.80 | 0.88 | 0.87 | 0.87 | 0.88 | 0.87 | 0.87 |
| Jaccard | 0.73 | 0.79 | 0.75 | 0.75 | 0.72 | 0.69 | 0.81 | 0.79 | 0.79 | 0.80 | 0.79 | 0.77 |
| Det. Quality (DQ) | 0.73 | 0.88 | 0.77 | 0.63 | 0.68 | 0.55 | 0.82 | 0.88 | 0.86 | 0.84 | 0.78 | 0.75 |
| Seg. Quality (SQ) | 0.73 | 0.79 | 0.75 | 0.75 | 0.72 | 0.69 | 0.81 | 0.79 | 0.79 | 0.80 | 0.79 | 0.77 |
4 Discussion & conclusion
We introduced Sketchpose, an open-source plugin to extend the applicability of Omnipose to partial annotations. From a methodological aspect, we developed a theory making it possible to use distance functions, despite having only access to partial information on the objects boundaries. From a more practical viewpoint, we developed an interactive interface within Napari, which facilitates efficient online learning with a real-time visualization of the training progress. The multi-threaded implementation allows users to continue annotating while the neural network trains or infers.
The new training procedure was tested in three different frames: i) training a neural network from scratch and just a few strokes, ii) improving the weights of a pre-trained network (a.k.a. transfer learning or human in the loop), iii) training with massive, but partial annotations.
For point i), frugal annotation works surprisingly well on a few test cases despite really limited information. A dozen strokes are already enough to provide results on par – or better – than pre-trained networks.
For point ii), our experiments demonstrated the potential benefits of using transfer learning. That is, starting with a pre-trained Omnipose models, we can further refine it using our methodology.
As for point iii), the conclusions are diverse. For datasets containing simple object shapes, such as PanNuke, it seems that a limited number of annotations (down to 25%) is sufficient to achieve results on par or even better than complete annotations. For more complex objects, it seems that complete annotations are still preferable. These conclusions should be validated on a case by case basis, but the ability to annotate while training make it possible to take the minimal amount of annotation time for a given task.
The method also shows a few limitations. First, it would benefit from faster training times to make the method even more interactive. We plan to improve this aspect in the forthcoming versions. Second, it is important to mention that our formalism is currently restricted to the two dimensional setting with two labels (background / foreground). Extending the methodology to numerous classes is rather straightforward, and the proposed ideas extend directly to this case. However, the proposed strategy do not extend to 3D directly. It could be used if the user was able to delineate a surface surrounding the objects of interest, but not just curves in 2D. Indeed, this would result in an empty valid distance set (see Theorem 4) and unadapted loss functions. This limitation of the method must be put into perspective by the fact that even the Cellpose 3D model is based on 2D predictions only, which are aggregated in post-processing.
In summary, the proposed method demonstrated numerous qualities in 2D for partial annotations. We showed that it is possible to train complex networks with a few sketches, reducing the annotation burden significantly. Further developments are needed to accelerate the training process and for a multi-class extension in 3D.
Acknowledgments
C. Cazorla was a recipient of ANRT (Agence Nationale pour la Recherche et la Technologie) in the context of the CIFRE Ph.D. program (N°2020/0843) with Imactiv-3D and Institut de Mathématiques de Toulouse (IMT). P. Weiss acknowledges a support from ANR-3IA Artificial and Natural Intelligence Toulouse Institute ANR-19-PI3A-0004 and from the ANR Micro-Blind ANR-21-CE48-0008. This work was performed using HPC resources from GENCI-IDRIS (Grant 2021-AD011012210R1).
We are grateful for the information provided by Kevin John Cutler about the original Omnipose implementation. The authors acknowledge Atlantic Bone Screen for providing the osteoclasts image and DIVA Expertise for providing the adipocytes image.
Ethical Standards
The work follows appropriate ethical standards in conducting research and writing the manuscript, following all applicable laws and regulations regarding treatment of animals or human subjects.
Conflicts of Interest
We declare we don’t have conflicts of interest.
Data availability
The code is available there: https://bitbucket.org/koopa31/napari-sketchpose/src/master/. The documentation is available there: https://sketchpose-doc.readthedocs.io/en/latest/.
References
- Arzt et al. (2022) Matthias Arzt, Joran Deschamps, Christopher Schmied, Tobias Pietzsch, Deborah Schmidt, Pavel Tomancak, Robert Haase, and Florian Jug. Labkit: labeling and segmentation toolkit for big image data. Frontiers in computer science, 4:10, 2022.
- Bai and Urtasun (2017) Min Bai and Raquel Urtasun. Deep watershed transform for instance segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5221–5229, 2017.
- Berg et al. (2019) Stuart Berg, Dominik Kutra, Thorben Kroeger, Christoph N Straehle, Bernhard X Kausler, Carsten Haubold, Martin Schiegg, Janez Ales, Thorsten Beier, Markus Rudy, et al. Ilastik: interactive machine learning for (bio) image analysis. Nature methods, 16(12):1226–1232, 2019.
- Bourdens et al. (2019) Marion Bourdens, Yannick Jeanson, Marion Taurand, Noémie Juin, Audrey Carrière, Franck Clément, Louis Casteilla, Anne-Laure Bulteau, and Valérie Planat-Bénard. Short exposure to cold atmospheric plasma induces senescence in human skin fibroblasts and adipose mesenchymal stromal cells. Scientific reports, 9(1):8671, 2019.
- Budd et al. (2021) Samuel Budd, Emma C Robinson, and Bernhard Kainz. A survey on active learning and human-in-the-loop deep learning for medical image analysis. Medical Image Analysis, 71:102062, 2021.
- Caicedo et al. (2019) Juan C. Caicedo, Jonathan Roth, Allen Goodman, Tim Becker, Kyle W. Karhohs, Matthieu Broisin, Csaba Molnar, Claire McQuin, Shantanu Singh, Fabian J. Theis, and Anne E. Carpenter. Evaluation of deep learning strategies for nucleus segmentation in fluorescence images. Cytometry Part A, 95(9):952–965, 2019. . URL https://onlinelibrary.wiley.com/doi/abs/10.1002/cyto.a.23863.
- Chiu et al. (2022) Chi-Li Chiu, Nathan Clack, et al. napari: a python multi-dimensional image viewer platform for the research community. Microscopy and Microanalysis, 28(S1):1576–1577, 2022.
- Cui et al. (2024) Ziwei Cui, Jingfeng Yao, Lunbin Zeng, Juan Yang, Wenyu Liu, and Xinggang Wang. Lkcell: Efficient cell nuclei instance segmentation with large convolution kernels. arXiv preprint arXiv:2407.18054, 2024.
- Cutler et al. (2022) Kevin J Cutler, Carsen Stringer, Teresa W Lo, Luca Rappez, Nicholas Stroustrup, S Brook Peterson, Paul A Wiggins, and Joseph D Mougous. Omnipose: a high-precision morphology-independent solution for bacterial cell segmentation. Nature methods, 19(11):1438–1448, 2022.
- Gamper et al. (2019) Johanna Gamper, Navid Alemi Koohbanani, Katarzyna Benet, Adnan Khuram, and Nasir Rajpoot. Pannuke: an open pan-cancer histology dataset for nuclei instance segmentation and classification. In European Congress on Digital Pathology (ECDP), pages 11–19. Springer, 2019. . URL https://doi.org/10.1007/978-3-030-23937-4_11.
- Graham et al. (2019) Simon Graham, Quoc Dang Vu, Shan E Ahmed Raza, Ayesha Azam, Yee Wah Tsang, Jin Tae Kwak, and Nasir Rajpoot. Hover-net: Simultaneous segmentation and classification of nuclei in multi-tissue histology images. Medical Image Analysis, 58:101563, 2019.
- He et al. (2017) Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. Mask r-cnn. In Proceedings of the IEEE international conference on computer vision, pages 2961–2969, 2017.
- Hörst et al. (2024) Fabian Hörst, Moritz Rempe, Lukas Heine, Constantin Seibold, Julius Keyl, Giulia Baldini, Selma Ugurel, Jens Siveke, Barbara Grünwald, Jan Egger, et al. Cellvit: Vision transformers for precise cell segmentation and classification. Medical Image Analysis, 94:103143, 2024.
- Kass et al. (1988) Michael Kass, Andrew Witkin, and Demetri Terzopoulos. Snakes: Active contour models. International journal of computer vision, 1(4):321–331, 1988.
- Kumar et al. (2019) Jitendra Kumar, R. Srivastava, R. Srivastava, A. Mehrotra, R. Srivastava, R. Srivastava, and R. Srivastava. Deep learning framework for recognition of diabetic retinopathy using monocular color fundus images. Computers in Biology and Medicine, 109:283–293, 2019. .
- Labour et al. (2016) Marie-Noëlle Labour, Mathieu Riffault, Søren T Christensen, and David A Hoey. Tgf1–induced recruitment of human bone mesenchymal stem cells is mediated by the primary cilium in a smad3-dependent manner. Scientific reports, 6(1):35542, 2016.
- Legland et al. (2016) David Legland, Ignacio Arganda-Carreras, and Philippe Andrey. Morpholibj: integrated library and plugins for mathematical morphology with imagej. Bioinformatics, 32(22):3532–3534, 2016.
- Lempitsky et al. (2018) Victor Lempitsky, Andrea Vedaldi, and Dmitry Ulyanov. Deep image prior. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9446–9454. IEEE, 2018.
- Naylor et al. (2018) Peter Naylor, Marick Laé, Fabien Reyal, and Thomas Walter. Segmentation of nuclei in histopathology images by deep regression of the distance map. IEEE transactions on medical imaging, 38(2):448–459, 2018.
- Otsu (1979) Nobuyuki Otsu. A threshold selection method from gray-level histograms. IEEE transactions on systems, man, and cybernetics, 9(1):62–66, 1979.
- Pachitariu and Stringer (2022) Marius Pachitariu and Carsen Stringer. Cellpose 2.0: how to train your own model. Nature methods, 19(12):1634–1641, 2022.
- Peters (2022) Ryan Peters. Torchvf: Vector fields for instance segmentation. 2022.
- Ronneberger et al. (2015) Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18, pages 234–241. Springer, 2015.
- Sadick et al. (2015) Neil S Sadick, Andrew S Dorizas, Nils Krueger, and Amer H Nassar. The facial adipose system: its role in facial aging and approaches to volume restoration. Dermatologic Surgery, 41:S333–S339, 2015.
- Scherr et al. (2022) Tim Scherr, Johannes Seiffarth, Bastian Wollenhaupt, Oliver Neumann, Dietrich Kohlheyer, Hanno Scharr, Katharina Nöh, and Ralf Mikut. microbeseg models, 2022. URL https://zenodo.org/record/7221151.
- Schmidt et al. (2018) Uwe Schmidt, Martin Weigert, Coleman Broaddus, and Gene Myers. Cell detection with star-convex polygons. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2018: 21st International Conference, Granada, Spain, September 16-20, 2018, Proceedings, Part II 11, pages 265–273. Springer, 2018.
- Serra and Soille (2012) Jean Serra and Pierre Soille. Mathematical morphology and its applications to image processing, volume 2. Springer Science & Business Media, 2012.
- Stringer and Pachitariu (2025) Carsen Stringer and Marius Pachitariu. Cellpose3: one-click image restoration for improved cellular segmentation. Nature methods, 22(3):592–599, 2025.
- Stringer et al. (2021) Carsen Stringer, Tim Wang, Michalis Michaelos, and Marius Pachitariu. Cellpose: a generalist algorithm for cellular segmentation. Nature methods, 18(1):100–106, 2021.
- Sugawara (2023) Ko Sugawara. Training deep learning models for cell image segmentation with sparse annotations. BioRxiv, pages 2023–06, 2023.
- Vincent and Soille (1991) Luc Vincent and Pierre Soille. Watersheds in digital spaces: an efficient algorithm based on immersion simulations. IEEE Transactions on Pattern Analysis & Machine Intelligence, 13(06):583–598, 1991.
- Zhu et al. (2021) Lillian Zhu, Manohary Rajendram, and Kerwyn Casey Huang. Effects of fixation on bacterial cellular dimensions and integrity. iScience, 24(4):102348, 2021. ISSN 2589-0042. . URL https://www.sciencedirect.com/science/article/pii/S2589004221003163.
A Proof of the valid distance set theorem
We start with a basic observation.
Proposition 5 (Properties of the distance function)
- •
.
- •
and .
Proof The first item is direct:
Here is one proof of the second iten by separating the two cases: either or .
- •
Case 1: . This case is trivial since by positivity of the distance.
- •
Case 2: . In that case, the key argument is to show that the open ball of radius centered in is included in . Precisely
(16) Indeed having Equation (16) established implies by contraposition that
(17) where the first inclusion is given by . Therefore, taking infimum with respect to these sets, implies the following inequalities and by the way the intended result.
So let’s prove Equation (16): by contradiction, assume that there exists . Notice that is a compact set (here denotes the closed segment between the points and ). Thus
is well defined and the semi-open segment is included in . This implies that since the sequence converges to . The contradiction comes from
The first inequality holds because , the second one because and last one because .
By proof by contradiction, Equation (16) holds.
In conclusion, in all cases the inequality is verified.
Theorem 4 can be proven in two steps. First, notice that the inclusion (Assumption 1) and the first bullet in Proposition 5 implies that for any .
Let’s establish the converse inequality. Let denote an arbitrary point in . Aiming for a proof by contradiction, assume that . We can proceed by separating two cases:
- •
Case 1: . This implies that since the set is closed as a finite union of closed sets . Moreover, as belongs to , in particular belongs to . It is sufficient to apply (11) and obtain which is inconsistent with .
- •
Case 2: . The point verifies as . Let us define and
by assumption. Since belongs to , there exists such that . Because , there exists a point such that
- –
Case 2.a: . By assumption (11), the contradiction comes quickly since now
(18) and this implies the contradictive inequality
- –
Case 2.b: . In that case, we may define the point on the line which is the nearest from the point and also in . Since , it implies a contradiction as intended:
The point is defined as where the map assigns to each scalar a point of the line and set
(19) Since and , the scalar is well defined. The remaining task is to show that . The argument works by construction and with a topological argument. Indeed, by definition of the infimum, there exists a sequence such that , thus . Also by definition, for all , , thus
- –
In both cases, the assumption leads to a contradiction. We deduce that .