Fairness Evaluation of Risk Estimation Models for Lung Cancer Screening
Shaurya Gaur1,2 , Michel Vitale1,3, Alessa Hering1, Johan Kwisthout2, Colin Jacobs1, Lena Philipp1, Fennie van der Graaf1
, Michel Vitale1,3, Alessa Hering1, Johan Kwisthout2, Colin Jacobs1, Lena Philipp1, Fennie van der Graaf1
1: Diagnostic Image Analysis Group, Department of Medical Imaging, Radboud University Medical Center, Nijmegen, the Netherlands, 2: Department of Artificial Intelligence, Radboud University, Nijmegen, the Netherlands, 3: Ethics of Healthcare Group, Department IQ Health, Radboud University Medical Center, Nijmegen, the Netherlands
Publication date: 2025/12/21
https://doi.org/10.59275/j.melba.2025-1e7f
Abstract
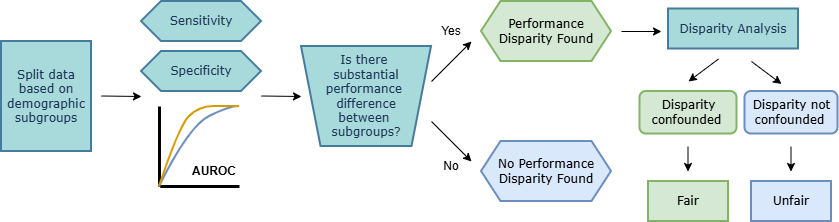
Lung cancer is the leading cause of cancer-related mortality in adults worldwide. Screening high-risk individuals with annual low-dose CT (LDCT) can support earlier detection and reduce deaths, but widespread implementation may strain the already limited radiology workforce. Artificial intelligence (AI) models have shown potential in estimating lung cancer risk from LDCT scans. However, high-risk populations for lung cancer are diverse, and these models’ performance across diverse demographic groups remains an open question. In this study, we used the JustEFAB ethical framework to evaluate potential performance disparities and fairness in two AI-based risk estimation models for lung cancer screening: the Sybil lung cancer risk model and the Venkadesh21 nodule risk estimator. We also examined disparities in the PanCan2b logistic regression model recommended in the British Thoracic Society nodule management guideline. Both AI-based models were trained on data from the U.S.-based National Lung Screening Trial (NLST), and assessed on a held-out NLST validation set. We evaluated area under the ROC curve (AUROC), sensitivity, and specificity across demographic subgroups, and explored potential confounding from clinical risk factors. We observed a statistically significant AUROC difference in Sybil’s performance between women (0.88, 95% CI: 0.86, 0.90) and men (0.81, 95% CI: 0.78, 0.84, p < .001). At 90% specificity, Venkadesh21 showed lower sensitivity for Black (0.39, 95% CI: 0.23, 0.59) than White participants (0.69, 95% CI: 0.65, 0.73). These differences were not explained by available clinical confounders and may be classified as unfair biases according to JustEFAB. Our findings highlight the importance of improving and monitoring model performance across underrepresented subgroups in lung cancer screening, as well as further research on algorithmic fairness in this field.
Keywords
Lung Cancer Screening · Pulmonary Nodule · Lung CT Scans · Deep Learning · Medical Imaging · Machine Learning · AI Bias · Subgroup Performance Analysis · Brock Model · Cancer Risk Estimation Models · Algorithmic Fairness · Ethically Significant Bias · AI for Screening · Confounder Assessment · JustEFAB · Fair ML · Responsible AI · Healthcare ML Algorithms · Clinical Decision Support Systems
Bibtex
@article{melba:2025:025:gaur,
title = "Fairness Evaluation of Risk Estimation Models for Lung Cancer Screening",
author = "Gaur, Shaurya and Vitale, Michel and Hering, Alessa and Kwisthout, Johan and Jacobs, Colin and Philipp, Lena and van der Graaf, Fennie",
journal = "Machine Learning for Biomedical Imaging",
volume = "3",
issue = "Special issue on FAIMI",
year = "2025",
pages = "559--593",
issn = "2766-905X",
doi = "https://doi.org/10.59275/j.melba.2025-1e7f",
url = "https://melba-journal.org/2025:025"
}
RIS
TY - JOUR
AU - Gaur, Shaurya
AU - Vitale, Michel
AU - Hering, Alessa
AU - Kwisthout, Johan
AU - Jacobs, Colin
AU - Philipp, Lena
AU - van der Graaf, Fennie
PY - 2025
TI - Fairness Evaluation of Risk Estimation Models for Lung Cancer Screening
T2 - Machine Learning for Biomedical Imaging
VL - 3
IS - Special issue on FAIMI
SP - 559
EP - 593
SN - 2766-905X
DO - https://doi.org/10.59275/j.melba.2025-1e7f
UR - https://melba-journal.org/2025:025
ER -