From Prompts to Pipelines: Evaluating LLM-Generated Medical Image Segmentation Baselines
Jasmin Arjomandi1 , Luisa Neubig1, Franziska Mathis-Ullrich1, Andreas M. Kist1
, Luisa Neubig1, Franziska Mathis-Ullrich1, Andreas M. Kist1
1: Department Artificial Intelligence in Biomedical Engineering, Friedrich-Alexander-Universität Erlangen-Nürnberg (FAU), Germany
Publication date: 2026/03/27
https://doi.org/10.59275/j.melba.2026-9369
Abstract
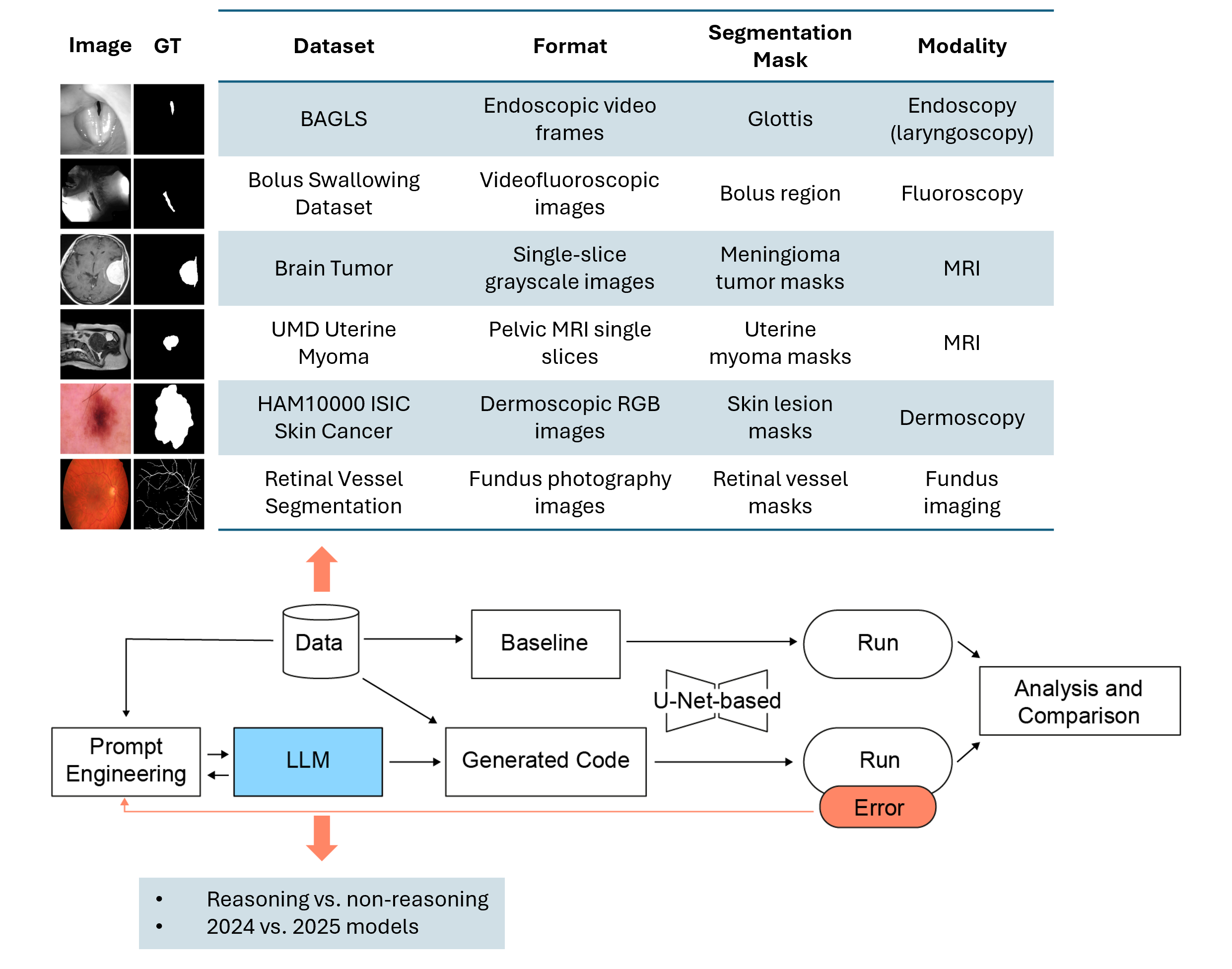
Large Language Models (LLMs) are increasingly applied to automate complex tasks, but their potential for generating automated medical image segmentation pipelines remains largely underexplored. We present a systematic evaluation of open- and closed-source LLMs in generating U-Net–based segmentation frameworks across six diverse 2D medical image datasets, spanning endoscopy, fluoroscopy, dermoscopic photography, MRI, and fundus imaging. Building on an earlier study, we analyze state-of-the-art 2025 reasoning-enabled models and compare them to non-reasoning LLMs and a strong nnU-Net v2 baseline. Compared to their 2024 predecessors, the 2025 models demonstrated marked improvements in robustness, code quality, and segmentation accuracy across modalities. Our results show that reasoning-augmented LLMs achieve faster convergence, fewer execution errors, and higher Dice scores, while complex datasets with fine structures (e.g., retinal vessels) and volumetric data remain challenging. We also confirmed robustness under repeated runs by comparing one reasoning and one non-reasoning model from the same family, where despite GPT-4o’s consistent, template-like code outputs under multiple runs as the non-reasoning model, GPT-o4-mini-high showed significantly lower run-to-run variability in validation loss and tighter Dice score distributions, demonstrating that chain-of-thought reasoning markedly improves both accuracy and stability. These findings highlight the potential of reasoning-enabled LLMs to automate segmentation workflows with high accuracy and explainability, paving the way for their integration into medical imaging pipelines. Our code is available at https://github.com/ankilab/LLM_based_Segmentation.git
Keywords
Large language Models (LLMs) · Medical Image Segmentation · Reasoning · Vibe Coding · Prompt Engineering · Chain-of-Thought
Bibtex
@article{melba:2026:009:arjomandi,
title = "From Prompts to Pipelines: Evaluating LLM-Generated Medical Image Segmentation Baselines",
author = "Arjomandi, Jasmin and Neubig, Luisa and Mathis-Ullrich, Franziska and Kist, Andreas M.",
journal = "Machine Learning for Biomedical Imaging",
volume = "2026",
issue = "MELBA–BVM 2025 Special Issue",
year = "2026",
pages = "159--183",
issn = "2766-905X",
doi = "https://doi.org/10.59275/j.melba.2026-9369",
url = "https://melba-journal.org/2026:009"
}
RIS
TY - JOUR
AU - Arjomandi, Jasmin
AU - Neubig, Luisa
AU - Mathis-Ullrich, Franziska
AU - Kist, Andreas M.
PY - 2026
TI - From Prompts to Pipelines: Evaluating LLM-Generated Medical Image Segmentation Baselines
T2 - Machine Learning for Biomedical Imaging
VL - 2026
IS - MELBA–BVM 2025 Special Issue
SP - 159
EP - 183
SN - 2766-905X
DO - https://doi.org/10.59275/j.melba.2026-9369
UR - https://melba-journal.org/2026:009
ER -